Atlas v1.2: Column-Level Lineage, Registry Backup Storage, Schema Ownership Policy, and More

Hey everyone!
We're excited to announce Atlas v1.2. This release brings column-level data lineage to Atlas Cloud, registry backups to your own cloud storage, a schema ownership policy for CI, and expanded database coverage.
Here is what you can find in this release:
- Column-Level Data Lineage - Trace how columns are derived from upstream sources across tables, views, and datasets in Atlas Cloud.
- Offline Access & Registry Backups - Back up Atlas Registry repositories to S3, GCS, or Azure Blob Storage. Atlas Pro license grants are cached in CI/CD environments, so your pipeline never has a single point of failure.
- Schema Ownership Policy - Enforce which GitHub users and teams can modify specific schema objects, closing the gap between CODEOWNERS and DDL access control.
- Database Driver Improvements - PostgreSQL routine permissions, user-mapping, and default ACLs; Snowflake tasks and pipes; Oracle UDTs; Expanded permissions for MSSQL, MySQL, and ClickHouse.
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
Column-Level Data Lineage
Atlas Cloud now traces column-level data lineage across tables, views, and datasets. Select any column to see where its data comes from, which transformation expressions shape it, and what downstream objects depend on it.
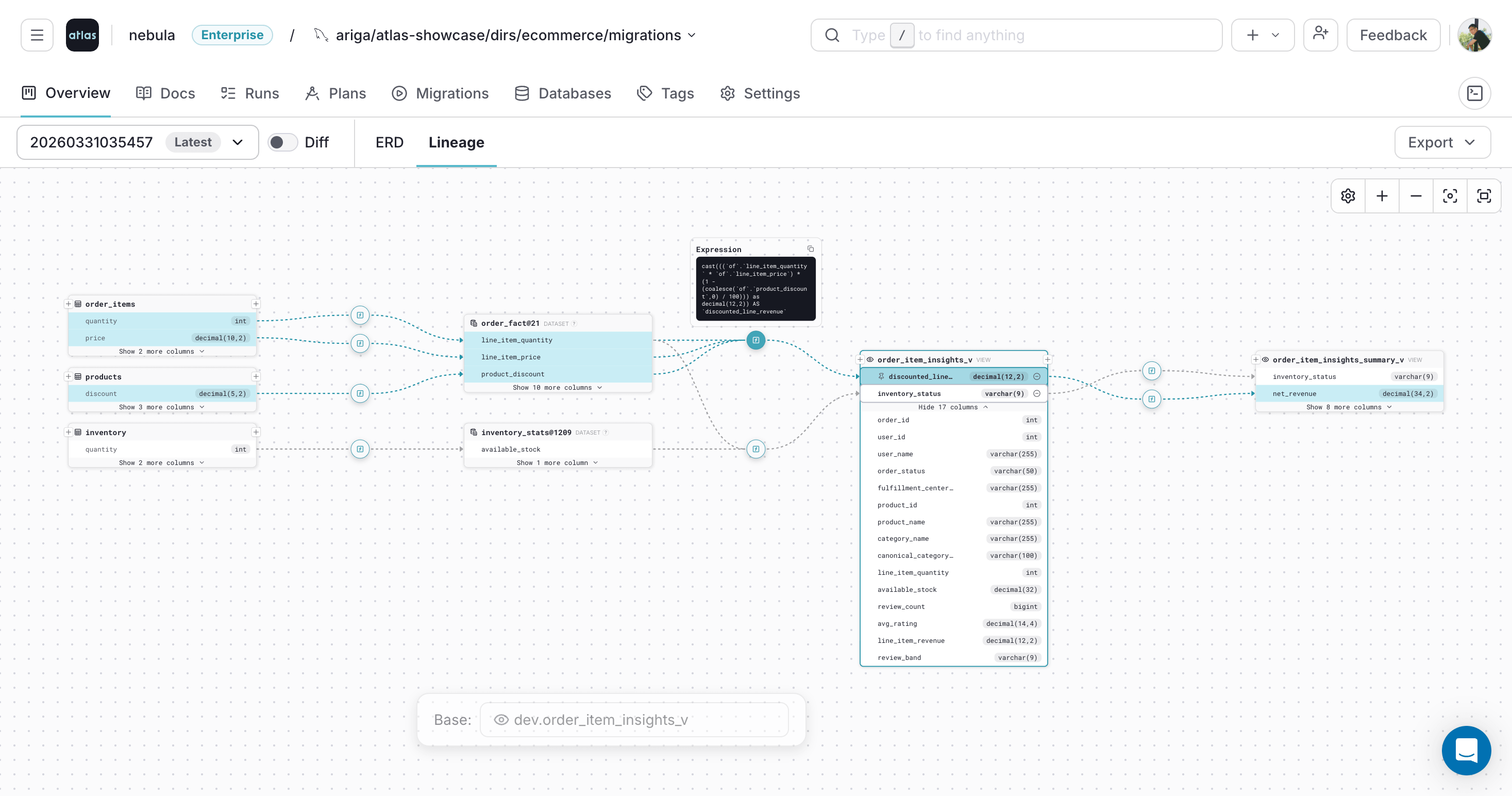
Tracing column lineage with pinned transformation expressions
Lineage is supported for PostgreSQL, MySQL, ClickHouse, CockroachDB, and Snowflake (including dynamic tables). Tables or data sources referenced in queries but not defined in the current schema appear as external dataset nodes, letting you trace lineage beyond the boundaries of your managed schema.
To learn more, see the data lineage documentation.
Offline Access & Registry Backups
As part of a broader business continuity strategy, this release adds two features to Atlas that ensure your deployment pipeline keeps running autonomously, with no single point of failure.
Atlas Pro now supports license grant caching, so CI/CD jobs continue using Atlas Pro capabilities even without connectivity to Atlas Cloud. GitHub Actions, GitLab CI, and CircleCI work out of the box with built-in caching. Bitbucket Pipelines requires a small cache configuration. The Kubernetes operator supports persistent volumes for grant caching across pod restarts.
Migration directories can now be backed up to your own storage with
registry backups. Atlas replicates every
atlas migrate push to one or more backup locations and falls back to them automatically on read.
Supported providers include AWS S3, Google Cloud Storage, and Azure Blob Storage:
- AWS S3
- Google Cloud Storage
- Azure Blob Storage
env "prod" {
migration {
dir = "atlas://app"
repo {
name = "app"
backup = [
"s3://my-atlas-backups/migrations?region=us-east-1",
]
}
}
}
env "prod" {
migration {
dir = "atlas://app"
repo {
name = "app"
backup = [
"gs://my-atlas-backups/migrations",
]
}
}
}
env "prod" {
migration {
dir = "atlas://app"
repo {
name = "app"
backup = [
"azureblob://my-container/migrations?storage_account=myaccount",
]
}
}
}
Our next version will extend backup storage to declarative workflows, automatically storing schemas and their plans alongside migration directories.
To learn more, see the offline access and backup repositories documentation.
Schema Ownership Policy
GitHub CODEOWNERS enforces who can modify files, but it cannot enforce who can modify schema objects. A
developer with access to the inventory/ schema folder could alter the schema files to include an
ALTER TABLE public.users, a core table owned by another team, causing a migration that crosses schema boundaries.
This is especially relevant as AI agents become more autonomous: they optimize for their goal and may modify any object that gets them there, regardless of ownership boundaries.
Atlas v1.2 introduces the ownership policy: a lint check that validates migration changes only touch
resources the author is authorized to modify. Define allow and deny blocks in your atlas.hcl to
specify which GitHub users or teams can modify matched schema objects:
lint {
ownership "github" {
allow "core-tables" {
match = "public.*[type=table]"
teams = ["backend"]
users = ["a8m"]
}
allow "inventory" {
match = "inventory.*"
teams = ["logistics"]
}
deny "contractors" {
match = "*"
users = ["contractor-x"]
}
}
}
When a violation is detected, Atlas posts a comment on the pull request:
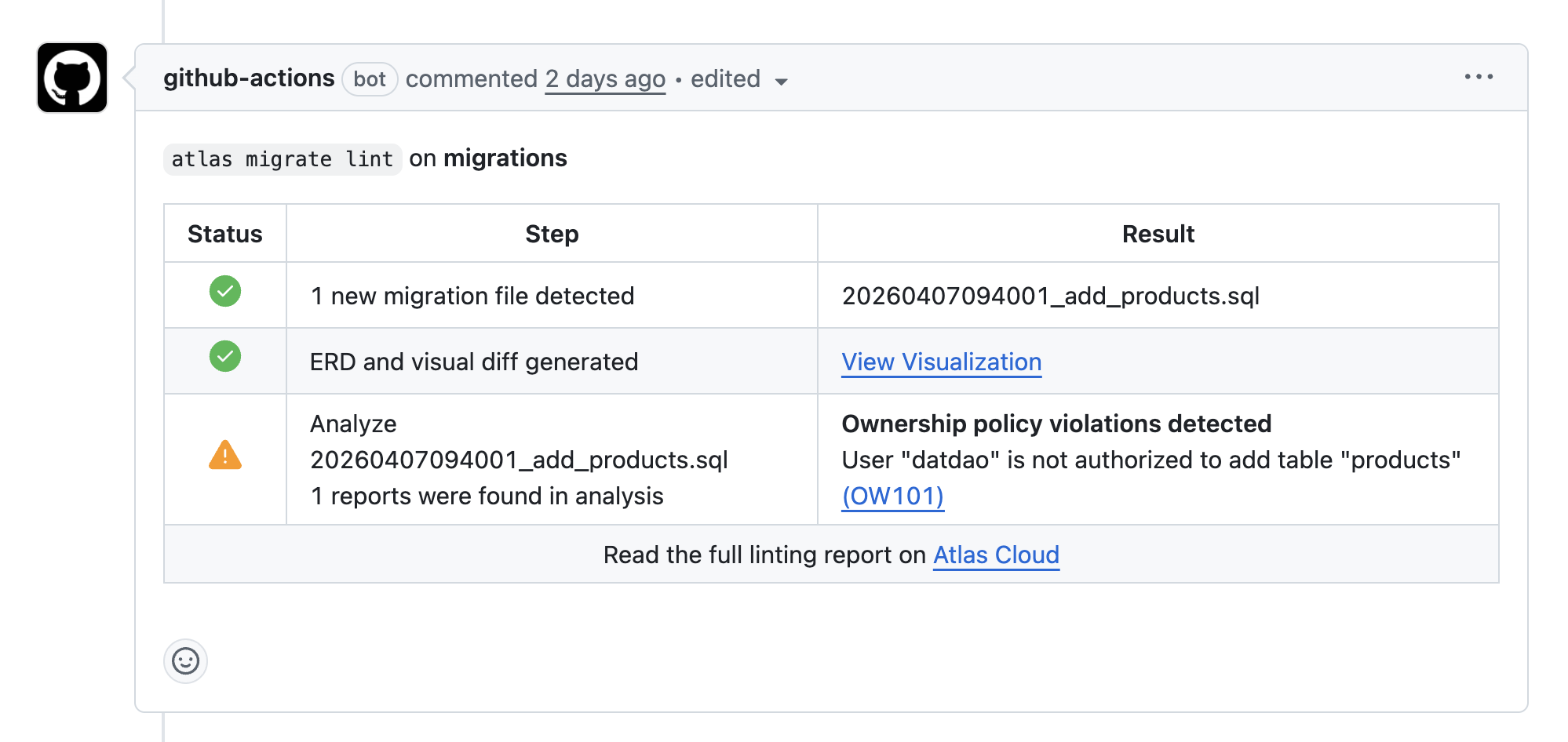
Atlas blocks a PR that crosses schema boundaries
To learn more, see the ownership policy guide and the analyzers reference.
Database Driver Improvements
Beyond the headline features, we spent time in this release speeding up our parsers and optimizing internal operations across all drivers. Here are the driver-specific highlights:
PostgreSQL
- Routine and materialized view permissions:
GRANT/REVOKEfor functions, procedures, and materialized views, with overloaded routine handling and column-level grants. - Default ACL management: Atlas inspects
pg_default_acland automatically revokes undeclared default privileges in HCL schemas. - User mappings for foreign data wrappers are now first-class resources.
Snowflake
- Tasks and pipes: Tasks support scheduling, DAG dependencies,
conditional execution, and session parameters. Pipes support continuous data loading with
COPY INTO. - Functions and procedures: All Snowflake languages (SQL, JavaScript, Python, Java), overloading, and secure mode.
- File formats as named resources, referenced from stages and external tables.
- Dynamic table improvements:
cluster_by, refresh mode extraction, and column type display in HCL. - Security views and
MAP(Key, Value)type support.
MySQL
- Routine permissions for functions and procedures.
- New lint checks (MY130-MY136): Blocking change detection for table copies, DML-blocking foreign keys, and primary key rebuilds.
ClickHouse
- Wildcard grants (
GRANT SELECT ON db.prefix*) for pattern-based permissions. - Vector similarity index for approximate nearest neighbor search on embedding columns.
Oracle
- User-defined types (UDTs) with methods, PL/SQL types, and system-defined data types.
VECTORandJSONcolumn data types.
SQL Server
- Type-level permissions and ACL support.
- Routine permissions for functions and procedures.
What's Next
This release also ships variable validation blocks
for input constraints, repository rules for enforcing naming conventions
in Atlas Cloud, and data skip_diff to exclude columns
with dynamic defaults like now() from data comparison. We ship improvements continuously between
releases, so follow the Atlas changelog to stay up to date.
Here's what's expected in the upcoming release:
- NoSQL database support for MongoDB, Amazon DocumentDB, DynamoDB, and others.
- Declarative backup storage, extending backup URLs to the declarative workflow, automatically storing schemas and their plans alongside migration directories.
- Security graph: Map access paths across your databases, surface overprivileged roles, and identify permission risks before they become incidents.
Wrapping Up
Atlas v1.2 brings schema governance with the ownership policy, full observability with column-level data lineage, resilience with offline access and registry backups, and continued expansion across Oracle, Snowflake, PostgreSQL, MSSQL, MySQL, and ClickHouse.
We'd love to hear your feedback! Join our Discord server or schedule a demo.