Announcing v0.23: Redshift Support, CircleCI Integration and More

Hi everyone,
It's been a few weeks since the release of v0.22, and we're excited to be back with the next version of Atlas, packed with some long awaited features and improvements.
- Redshift Support - Amazon Redshift, a fully managed, petabyte-scale data warehouse service in the cloud. Starting today, you can use Atlas to manage your Redshift Schema-as-Code.
- CircleCI Integration - Following some recent requests from our Enterprise customers, we have added a CircleCI orb to make it easier to integrate Atlas into your CircleCI pipelines.
- Kubernetes Operator Down Migrations - The Kubernetes Operator now detects when you are moving to a previous version and will attempt to apply a down migration if configured to do so.
- GORM View Support - We have added support for defining SQL Views in your GORM models.
- SQLAlchemy Provider Improvements - We have added support for defining models using SQLAlchemy Core Tables in the SQLAlchemy provider.
- ERD v2 - We have added a new navigation sidebar to the ERD to make it easier to navigate within large schemas.
- PostgreSQL Improvements - We have added support for PostgreSQL Event Triggers, Aggregate Functions, and Function Security.
Let's dive in!
Redshift Beta Support
Atlas's "Database Schema-as-Code" is useful even for managing small schemas with a few tables, but it really shines when you have a large schema with many tables, views, and other objects. This is the common case instead of the exception when you are dealing with Data Warehouses like Redshift that aggregate data from multiple sources.
Data warehouses typically store complex and diverse datasets consisting of hundreds of tables with thousands of columns and relationships. Managing these schemas manually can be a nightmare, and that's where Atlas comes in.
Today we are happy to announce the beta support for Amazon Redshift in Atlas. You can now use Atlas to manage your Redshift schema, generate ERDs, plan and apply changes, and more.
To get started, first install the latest version of the Atlas CLI:
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
Next, login to your Atlas account to activate the Redshift beta feature:
atlas login
To verify Atlas is able to connect to your Redshift database, run the following command:
atlas schema inspect --url "redshift://<username>:<password>@<host>:<port>/<database>?search_path=<schema>"
If everything is working correctly, you should see the Atlas DDL representation of your Redshift schema.
To learn more about the Redshift support in Atlas, check out the documentation.
CircleCI Integration
CircleCI is a popular CI/CD platform that allows you to automate your software development process. With this version we have added a CircleCI orb to make it easier to integrate Atlas into your CircleCI pipeline. CircleCI orbs are reusable packages of YAML configuration that condense repeated pieces of config into a single line of code.
As an example, suppose you wanted to create a CircleCI pipeline that pushes your migration directory to your Atlas Cloud
Schema Registry. You can use the atlas-orb to simplify the configuration:
version: '2.1'
orbs:
atlas-orb: ariga/atlas-orb@0.0.3
workflows:
postgres-example:
jobs:
- push-dir:
context: the-context-has-ATLAS_TOKEN
docker:
- image: cimg/base:current
- environment:
POSTGRES_DB: postgres
POSTGRES_PASSWORD: pass
POSTGRES_USER: postgres
image: cimg/postgres:16.2
steps:
- checkout
- atlas-orb/setup:
cloud_token_env: ATLAS_TOKEN
version: latest
- atlas-orb/migrate_push:
dev_url: >-
postgres://postgres:pass@localhost:5432/postgres?sslmode=disable
dir_name: my-cool-project
Let's break down the configuration:
- The
push-dirjob uses thecimg/postgres:16.2Docker image to run a PostgreSQL database. This database will be used as the Dev Database for different operations performed by Atlas. - The
atlas-orb/setupstep initializes the Atlas CLI with the providedATLAS_TOKENenvironment variable. - The
atlas-orb/migrate_pushstep pushes the migration directorymy-cool-projectto the Atlas Cloud Schema Registry.
To learn more about the CircleCI integration, check out the documentation.
Kubernetes Operator Down Migrations
The Atlas Operator is a Kubernetes operator that enables you to manage your database
schemas using Kubernetes Custom Resources. In one of our recent releases, we added
support for the migrate down command to the CLI. Using this command, you can roll back applied migrations
in a safe and controlled way, without using pre-planned down migration scripts or manual intervention.
Starting with v0.5.0, the Atlas Operator supports
down migrations as well. When you change the desired version of your database for a given AtlasMigration resource, the operator
will detect whether you are moving to a previous version and will attempt to apply a down migration if you configured it
to do so.
Down migrations are controlled via the new protectedFlows field in the AtlasMigration resource. This field allows you
to specify the policy for down migrations. The following policy, for example, allows down migrations and auto-approves them:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasMigration
metadata:
name: atlasmig-mysql
spec:
protectedFlows:
migrateDown:
allow: true
autoApprove: true
# ... redacted for brevity
Alternatively, Atlas Cloud users may set the autoApprove field to false to require manual approval for down migrations.
In this case, the operator will pause the migration and wait for the user to approve the down migration before proceeding:
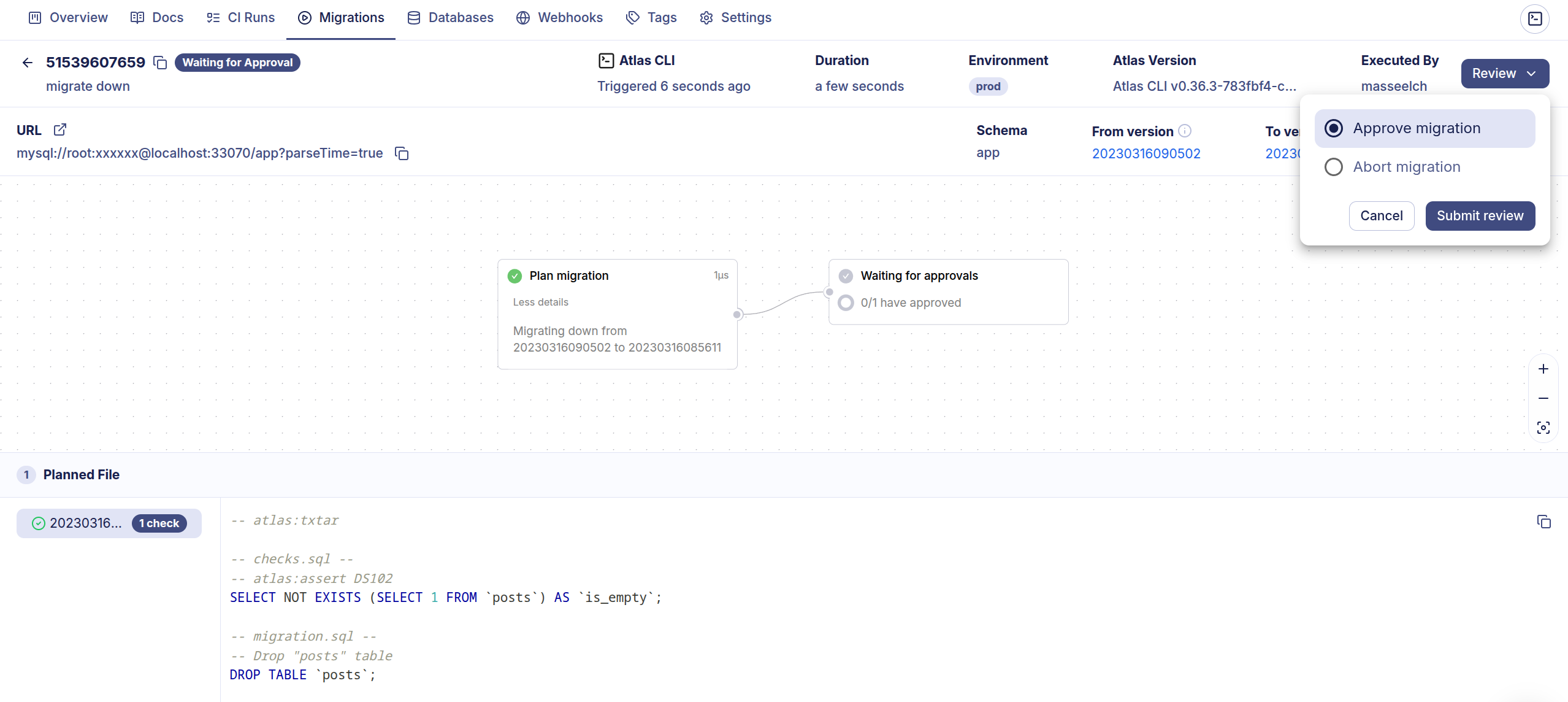
ERD v2
When you push your migration directory to the Atlas Cloud Schema Registry, Atlas generates an ERD for your schema. The ERD is a visual representation of your schema that shows the different database objects in your schema and the relationships between them.
To make it easier to navigate within large schemas we have recently added a fresh new navigation sidebar to the ERD:
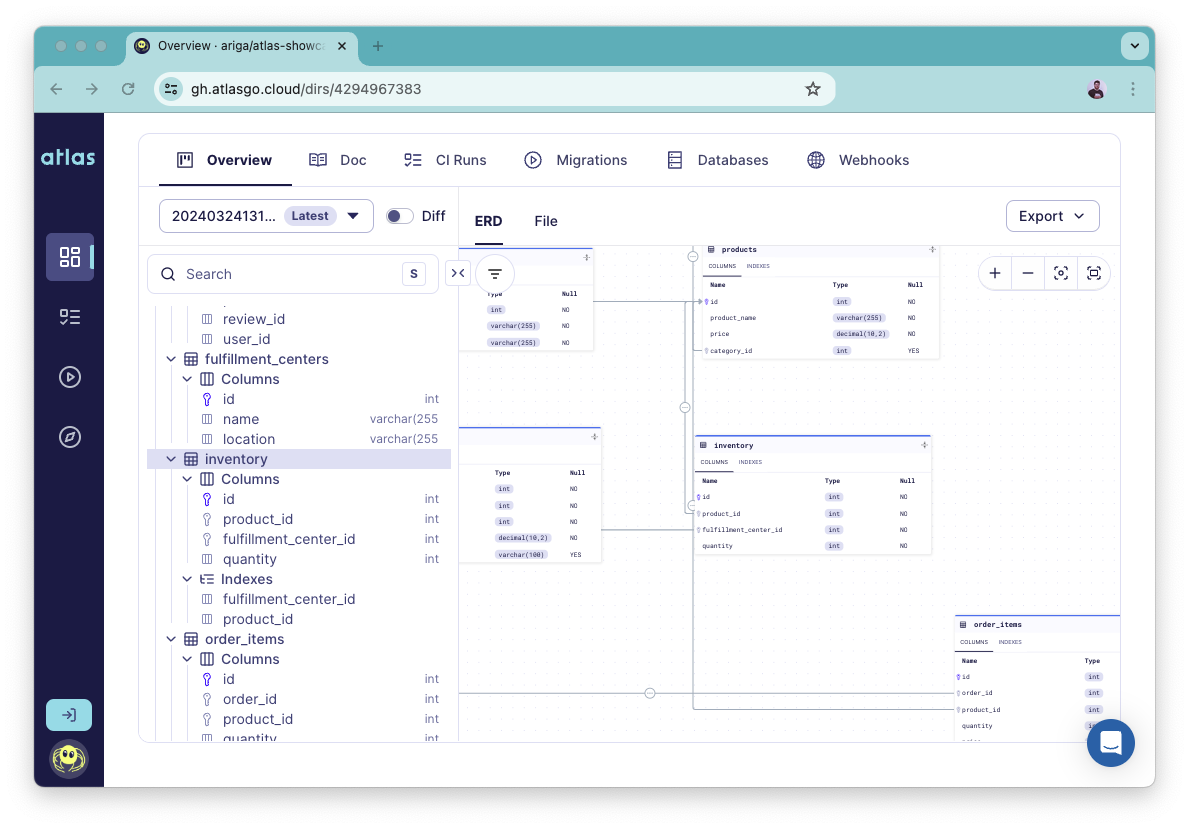
GORM View Support
GORM is a popular ORM library for Go that provides a simple way to interact with databases. The Atlas GORM provider provides a seamless integration between Atlas and GORM, allowing you to generate migrations from your GORM models and apply them to your database.
SQL Views are a powerful feature in relational databases that allow you to create virtual tables based on the result of a query. Managing views with GORM (and ORMs in general) is a notoriously clunky process, as they are normally not first-class citizens in the ORM world.
With v0.4.0, we have added a new API to the GORM provider that allows you to define views in your GORM models.
Here's a glimpse of how you can define a view in GORM:
// User is a regular gorm.Model stored in the "users" table.
type User struct {
gorm.Model
Name string
Age int
}
// WorkingAgedUsers is mapped to the VIEW definition below.
type WorkingAgedUsers struct {
Name string
Age int
}
func (WorkingAgedUsers) ViewDef(dialect string) []gormschema.ViewOption {
return []gormschema.ViewOption{
gormschema.BuildStmt(func(db *gorm.DB) *gorm.DB {
return db.Model(&User{}).Where("age BETWEEN 18 AND 65").Select("name, age")
}),
}
}
By implementing the ViewDefiner interface, GORM users can now include views in their GORM models and have Atlas
automatically generate the necessary SQL to create the view in the database.
To learn more about the GORM view support, check out the documentation.
Thanks to luantranminh for contributing this feature!
SQLAlchemy Provider Improvements
The Atlas SQLAlchemy provider allows you to generate migrations from your SQLAlchemy models and apply them to your database.
With v0.2.2, we have added support for defining models using SQLAlchemy Core Tables in addition to the existing support for ORM Models.
In addition, we have decoupled the provider from using a specific SQLAlchemy release, allowing users to use any version of SQLAlchemy they prefer. This should provide more flexibility and make it easier to integrate the provider into your existing projects.
Huge thanks to vshender for contributing these improvements!
Other Improvements
On our quest to support the long tail of lesser known database features we have recently added support for the following:
PostgreSQL Event Triggers
PostgreSQL Event Triggers are a special kind of trigger. Unlike regular triggers, which are attached to a single table and capture only DML events, event triggers are global to a particular database and are capable of capturing DDL events.
Here are some examples of how you can use event triggers in Atlas:
# Block table rewrites.
event_trigger "block_table_rewrite" {
on = table_rewrite
execute = function.no_rewrite_allowed
}
# Filter specific events.
event_trigger "record_table_creation" {
on = ddl_command_start
tags = ["CREATE TABLE"]
execute = function.record_table_creation
}
Aggregate Functions
Aggregate functions are functions that operate on a set of values and return a single value. They are commonly used
in SQL queries to perform calculations on groups of rows. PostgreSQL allows users to define custom aggregate functions
using the CREATE AGGREGATE statement.
Atlas now supports defining custom aggregate functions in your schema. Here's an example of how you can define an aggregate function in Atlas:
aggregate "sum_of_squares" {
schema = schema.public
arg {
type = double_precision
}
state_type = double_precision
state_func = function.sum_squares_sfunc
}
function "sum_squares_sfunc" {
schema = schema.public
lang = PLpgSQL
arg "state" {
type = double_precision
}
arg "value" {
type = double_precision
}
return = double_precision
as = <<-SQL
BEGIN
RETURN state + value * value;
END;
SQL
}
Function Security
PostgreSQL allows you to define the security level of a function using the SECURITY clause. The SECURITY clause
can be set to DEFINER or INVOKER. When set to DEFINER, the function is executed with the privileges of the
user that defined the function. When set to INVOKER, the function is executed with the privileges of the user that
invoked the function. This is useful when you want to create functions that execute with elevated privileges.
Atlas now supports defining the security level of functions in your schema. Here's an example of how you can define
a function with SECURITY DEFINER in Atlas:
function "positive" {
schema = schema.public
lang = SQL
arg "v" {
type = integer
}
return = boolean
as = "SELECT v > 0"
security = DEFINER
}
Wrapping Up
That's all for this release! We hope you try out (and enjoy) all of these new features and find them useful. As always, we would love to hear your feedback and suggestions on our Discord server.