Atlas: Like Terraform, but for Databases

Hello everyone,
Today, we're excited to release the new schema plan command, which many of you have been eagerly awaiting.
Taking the declarative workflow to the next level, the schema plan command lets you review, analyze and even edit
declarative migration plans at pull-request stage, making schema apply much safer and predictable. Additionally,
several new features have been added to Atlas in this release, and we'll cover them in this blog post as well.
What is Atlas?
For those visiting us for the first time, Atlas is a language-agnostic tool for managing and migrating database schemas using modern DevOps principles. Users define their desired database schema state declaratively, and Atlas handles the rest. The "state" can be defined using SQL, HCL (Atlas flavor), your preferred ORM, another database, or a combination of all. To get started, visit the getting-started doc.
Why schema plan?
Since the first release, Atlas supports declarative migrations. Using the schema apply command, users provide the desired schema,
and a URL (connection string) to the target database, and Atlas computes the migration plan, and applies it to the database
after the user approves it. This workflow is very similar to Terraform, but for databases schemas.
Although the declarative workflow feels magical, and works well for most cases, it had some inherent limitations:
- Since changes are computed at runtime, reviews also happen at runtime, either by policy (explained below) or manually. This creates a less predictable and streamlined deployment process compared to applications development, where code reviews occur during the pull request (PR) stage. Since Atlas promotes the "Schema as Code" approach, we aim to bring the same experience to database schema changes.
- Another limitation of this workflow is that users can define the desired state but have no control on the exact steps to reach it. Although Atlas provides a set of diff policies to fine-tune migration planning, users sometimes need more control over how the migrations are applied.
- Data changes, like back-filling columns with custom
UPDATEstatements, are difficult to express declaratively.
Fortunately, since Atlas provides also a versioned workflow, companies faced these limitations have been able to fall back to it. While versioned migration has its own limitations (like history linearity), it still works well for most cases. Combined with Atlas's automatic migration planning, the overall experience is closely to the declarative migration, but not the same.
We believe that declarative migration is the future for most cases. It lets engineers focus on feature development, not migrations. Additionally, this workflow allows schema transitions between any states, generating the most efficient plan, unlike versioned migration, which relies on a linear history of changes.
We address these limitations by introducing the schema plan command. Let's dive in.
What is schema plan?
The atlas schema plan command allows users to pre-plan, review, and approve declarative migrations before executing them
on the database. It lets users modify the SQL migration plan (if necessary), involve team members in the review, and
ensure the approval is done at development stage, and no human intervention is needed during deployment (atlas schema apply)
stage.
How does it work? Users modify their schema code (e.g., ORM models, SQL or HCL) and open a PR with the changes. Then, Atlas computes the migration plan, runs analysis, and simulates it on a dev-database. Lastly, it comments on the PR with the results:
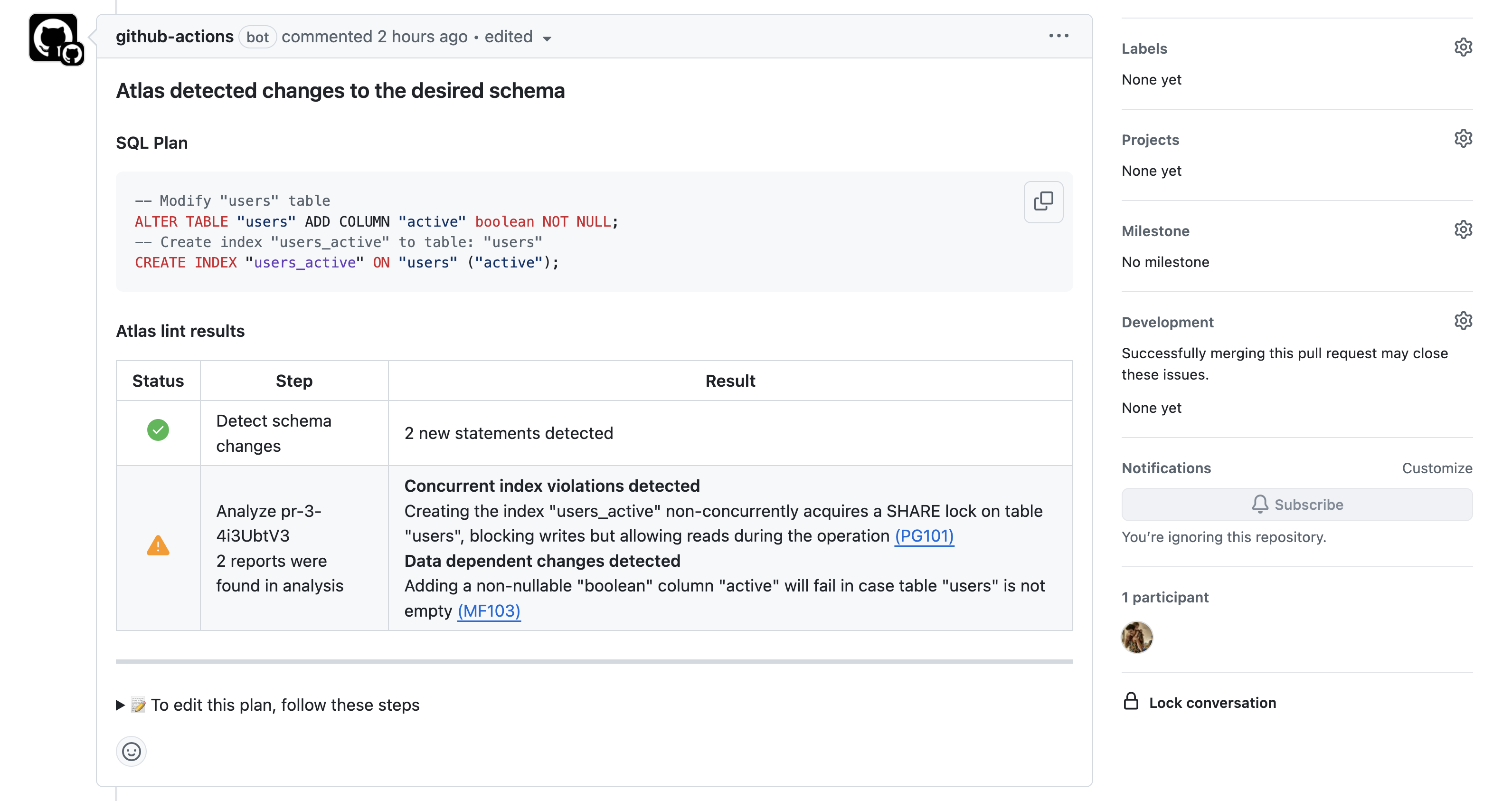
Plan Generated by atlas schema plan
Once the PR is approved and merged, the plan is saved in the Atlas Registry in a "ready to be applied" state.
During deployment (schema apply), Atlas checks for any pre-planned migration for the given schema transition
(State1 -> State2) and uses it if available, otherwise falling back to other approval policies.
This process can also be done locally, allowing users to plan and approve locally, then apply remotely.
If you follow our blog, you know we love practical examples. To maintain this tradition and demonstrate the new command, let’s dive into an example.
Example
Before running atlas schema plan, let's ensure that a schema repository named app exists in Atlas Registry and there
is a database containing the previous schema state (before our changes):
- Schema Definition
- Config File
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT
);
env "local" {
# URL to the target database.
url = "sqlite://main.db"
# URL to the dev-database.
dev = "sqlite://dev?mode=memory"
schema {
# Desired schema state.
src = "file://schema.sql"
# Atlas Registry config.
repo {
name = "app"
}
}
}
We run atlas schema push to create the schema in Atlas Registry:
atlas schema push --env local
Schema: app
-- Atlas URL: atlas://app
-- Cloud URL: https://a8m.atlasgo.cloud/schemas/141733920781
Then, we run atlas schema apply to align the database with the schema state:
atlas schema apply --env local --auto-approve
At this stage, our database main.db contains the users table with the id and name columns.
Changing the Schema
Suppose we want to add a non-nullable email column to the users table. Let's update the schema.sql file and then run
atlas schema plan to generate a migration plan.
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
email TEXT NOT NULL
);
We run atlas schema plan to generate a migration plan for adding the email column to the users table:
atlas schema plan --env local
The output looks like this:
Planning migration from local database to file://schema.sql (1 statement in total):
-- add column "email" to table: "users":
-> ALTER TABLE `users` ADD COLUMN `email` text NOT NULL;
-------------------------------------------
Analyzing planned statements (1 in total):
-- data dependent changes detected:
-- L2: Adding a non-nullable "text" column "email" will fail in case table "users"
is not empty https://atlasgo.io/lint/analyzers#MF103
-- ok (346.192µs)
-------------------------
-- 5.038728ms
-- 1 schema change
-- 1 diagnostic
? Approve or abort the plan:
▸ Approve and push
Abort
Data-Dependent Changes
Atlas detects data-dependent changes in the migration plan and provides a diagnostic message. In this case, it warns
that adding the non-nullable email column, will fail if the users table is not empty. The recommended solution is to
provide a default value for the new column. Let's fix this by adding a default value to the email column and re-run the
atlas schema plan command.
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
email TEXT NOT NULL DEFAULT 'unknown'
);
Then, we run atlas schema plan again to generate a new migration plan, but this time, we approve it:
atlas schema plan --env local
Planning migration from local database to file://schema.sql (1 statement in total):
-- add column "email" to table: "users":
-> ALTER TABLE `users` ADD COLUMN `email` text NOT NULL DEFAULT 'unknown';
-------------------------------------------
Analyzing planned statements (1 in total):
-- no diagnostics found
-------------------------
-- 6.393773ms
-- 1 schema change
? Approve or abort the plan:
▸ Approve and push
Abort
Once approved, the migration plan will be pushed to the Atlas Registry, and can be applied using atlas schema apply.
Plan Status: APPROVED
-- Atlas URL: atlas://app/plans/20240923085308
-- Cloud URL: https://a8m.atlasgo.cloud/schemas/141733920769/plans/210453397504
At this stage, we can run atlas schema apply to apply the changes to the database, on any environment, without
re-calculating the SQL changes at runtime or requiring human intervention.
Applying approved migration using pre-planned file 20240923085308 (1 statement in total):
-- add column "email" to table: "users"
-> ALTER TABLE `users` ADD COLUMN `email` text NOT NULL DEFAULT 'unknown';
-- ok (749.815µs)
-------------------------
-- 802.902µs
-- 1 migration
-- 1 sql statement
Atlas Registry
Starting with this release, Atlas Registry supports the declarative workflow. It allows you to store, version, and maintain a single source of truth for your database schemas and their migration plans.
It is similar to DockerHub, but for your schemas and migrations. In addition to functioning as storage and Atlas state management, it is schema-aware and provides extra capabilities such as ER diagrams, SQL diffing, schema docs, and more.
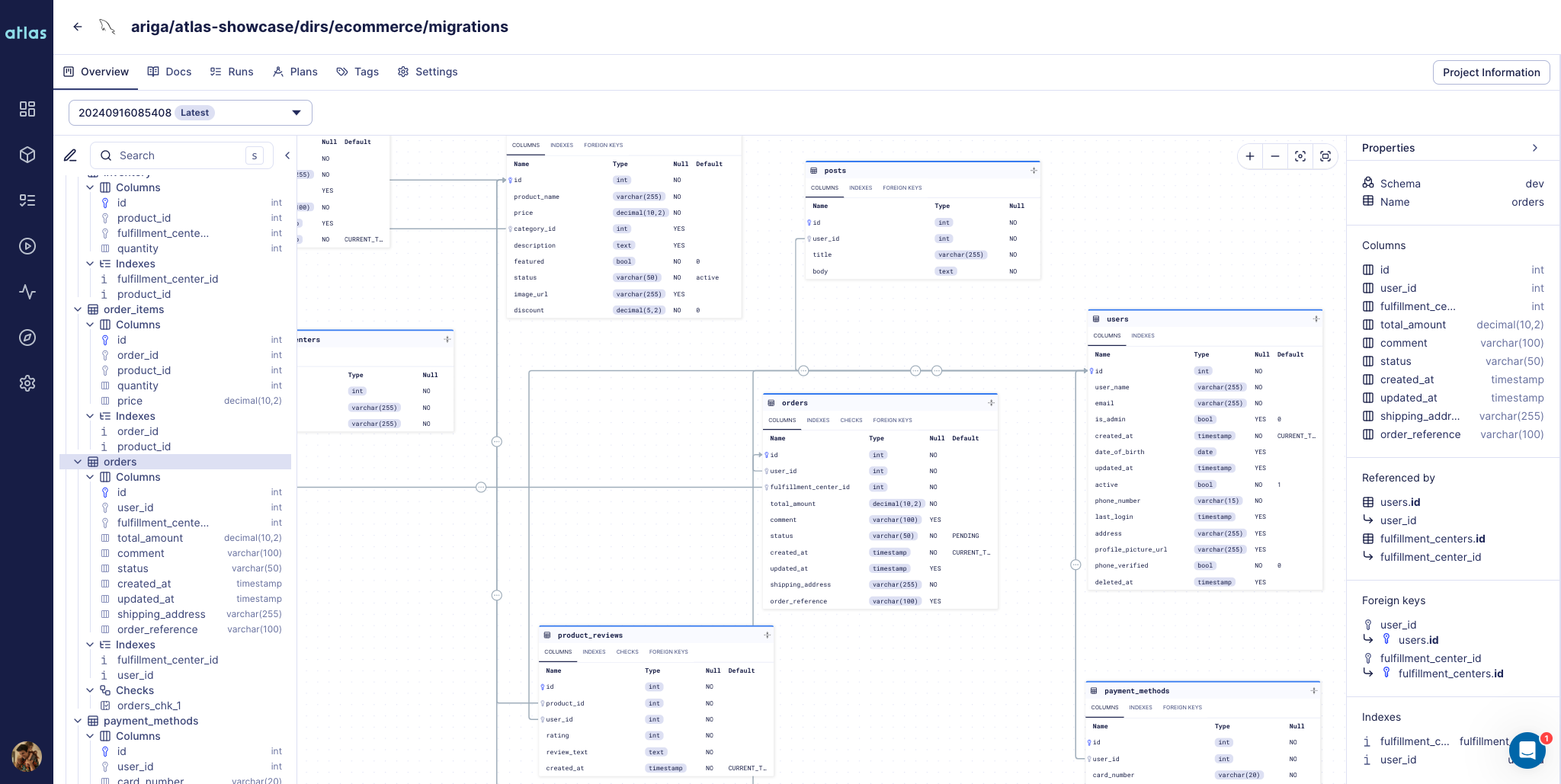
Schema pushed with atlas schema push
What else is new?
In addition to the schema plan command, we have added several new features and improvements to Atlas. Here are some highlights:
- Users running
atlas schema applywith a Pro license will now receive a detailed migration linting report and can control the approval based on it. Read more about the Review and Approval Policies. - The
schema applycommand now supports the--editflag, allowing users to safely edit the migration plan before applying it. Note that if your manual changes are not in sync with the desired state, Atlas will detect schema drift and reject the changes. - The GitHub Action and
ghextension for Atlas have been updated to support the new declarative workflow. - The ClickHouse driver now supports Dictionaries.
- The
dockerblock in Atlas config now supportsbuildblocks, allowing users to use custom Docker images for their dev-databases. - The PostgreSQL driver now supports configuring
DEFERRABLEconstraints on primary keys, foreign keys, unique, and exclusion constraints. - The
externalcommand was added to the Atlas testing framework, allowing users to run custom commands during the testing phase.
Wrapping Up
That's all for this release! But, we are already working on several features and improvements in the pipeline. To be transparent with our community, here is a look at what's coming next:
- Partition support for the PostgreSQL driver.
- CircleCI, GitLab CI, Kubernetes Operator, and Terraform Provider will support the new declarative workflow.
- A new
schema lintcommand, allowing users to lint their schemas with built-in and custom analyzers. - A Prisma provider for Atlas, enabling Prisma users to import their Prisma schema into Atlas schema state.
We hope you enjoy the new features and improvements. As always, we would love to hear your feedback and suggestions on our Discord server.