New Analyzers and Cloud Linting Configuration

It's been only two weeks since the release of v0.10.0, but we are already back with more exciting features we want to share with you. Besides some more improvements and bug fixes, we added two new SQL analyzers to Atlas and the capability to have Atlas Cloud pick up a linting configuration file from your repository.
Concurrent Index Policy (Postgres)
One of the Analyzers we added in this release is the
Concurrent Index Policy Analyzer for Postgres. When creating or
dropping indexes Postgres will lock the table against writes. Depending on the amount of data this lock might be in
place longer than just a few moments, up to several hours. Therefore, Postgres provides the CONCURRENTLY option
which will cause the index to be built without keeping a lock for the whole time it is built. While consuming more
resources, this option oftentimes is preferred, and we are happy to present to you, that Atlas Linting engine is now
capable of detecting statements that create or drop an index without using the CONCURRENTLY option.
Naming Conventions Policy
Keeping consistency when naming database schema resources is a widely common practice. Atlas now has an analyzer that can detect names that don't comply with a given naming policy and will warn you in such cases. You can configure both a global or a resource specific policy. Read on to learn how to configure this analyzer or have a look at the documentation.
Cloud Linting Configuration
In our last post, @a8m introduced the Community Preview for Atlas Cloud and how to connect a migration directory in your GitHub repository to Atlas Cloud with just a few clicks. As of then, the Atlas Cloud Linting reports that are added to your PR's used the default linting configuration. In this post, I will show you how to add configuration to the linting by making use of both the new analyzers I mentioned above.
- New Migration Directory
- Connected Migration Directory
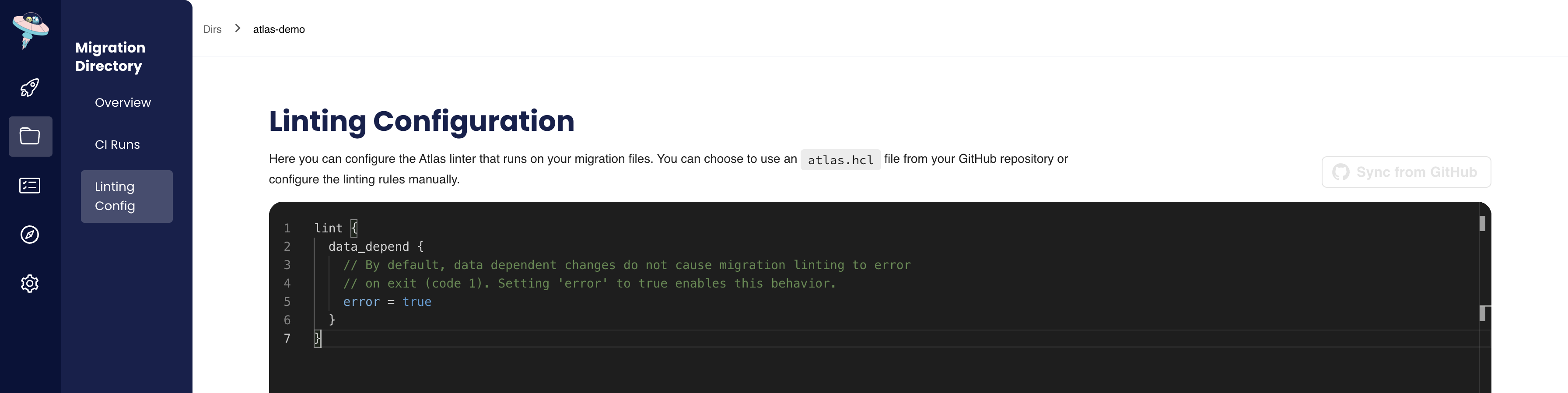
When connecting a new migration directory, Atlas Cloud will scan the repository for an existing atlas.hcl file
and propose to you to use that file on migration linting. If you don't have such a file, you can configure it manually
as described in the next tab.
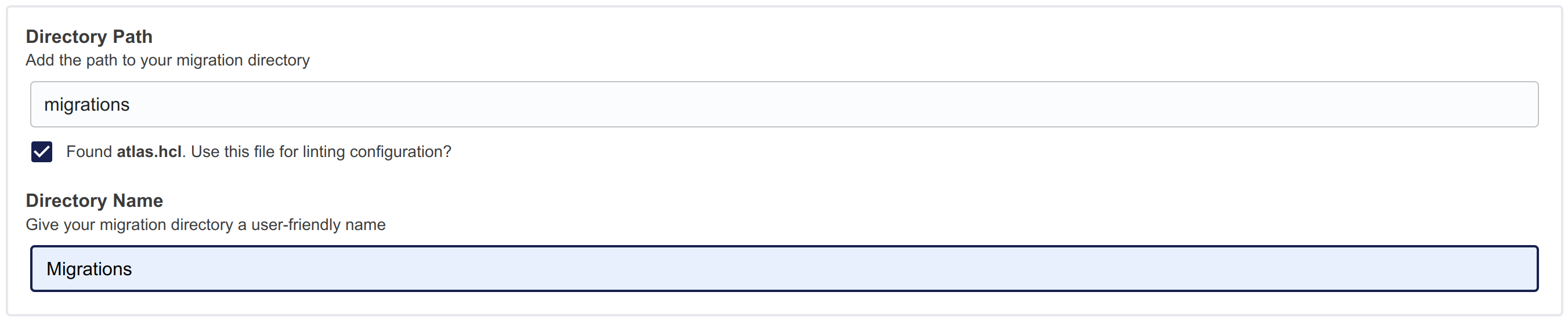
For an already connected migration directory, you can head over to the migration directory in Atlas Cloud
and connect an atlas.hcl file living in the same repository as your migration files or create one manually
in the Linting Config tab.
Enable the Analyzers
The Concurrent Index Analyzer will not report on creating or dropping indexes on tables that have been created in the same file. Therefore, lets ensure we have a table ready we can add an index to. Our first migration file can look something like this:
CREATE TABLE users
(
id serial PRIMARY KEY,
email VARCHAR(50) UNIQUE NOT NULL,
first_name VARCHAR(50) NOT NULL
);
To configure the Atlas Cloud linter to warn about creating or dropping indexes without the CONCURRENTLY option and
ensure that all our schema resources are named with lowercase letters only, use the following configuration:
The below configuration will also work with the latest release of the Atlas CLI.
lint {
concurrent_index {
error = true # block PR on violations instead of warning
}
naming {
error = true
match = "^[a-z]+$" # regex to match lowercase letters
message = "must be lowercase letters" # message to return if a violation is found
}
}
See It In Action
What is left to demonstrate is a migration file violating the above policies. Take the below example: the index name
contains an underscore _, which is permitted by the naming analyzer and create the index non-concurrently.
CREATE INDEX email_idx ON users (email);
After adding the above atlas.hcl configuration file and the new migration, create a Pull Request on GitHub and observe
Atlas Cloud doing its magic wizardry:
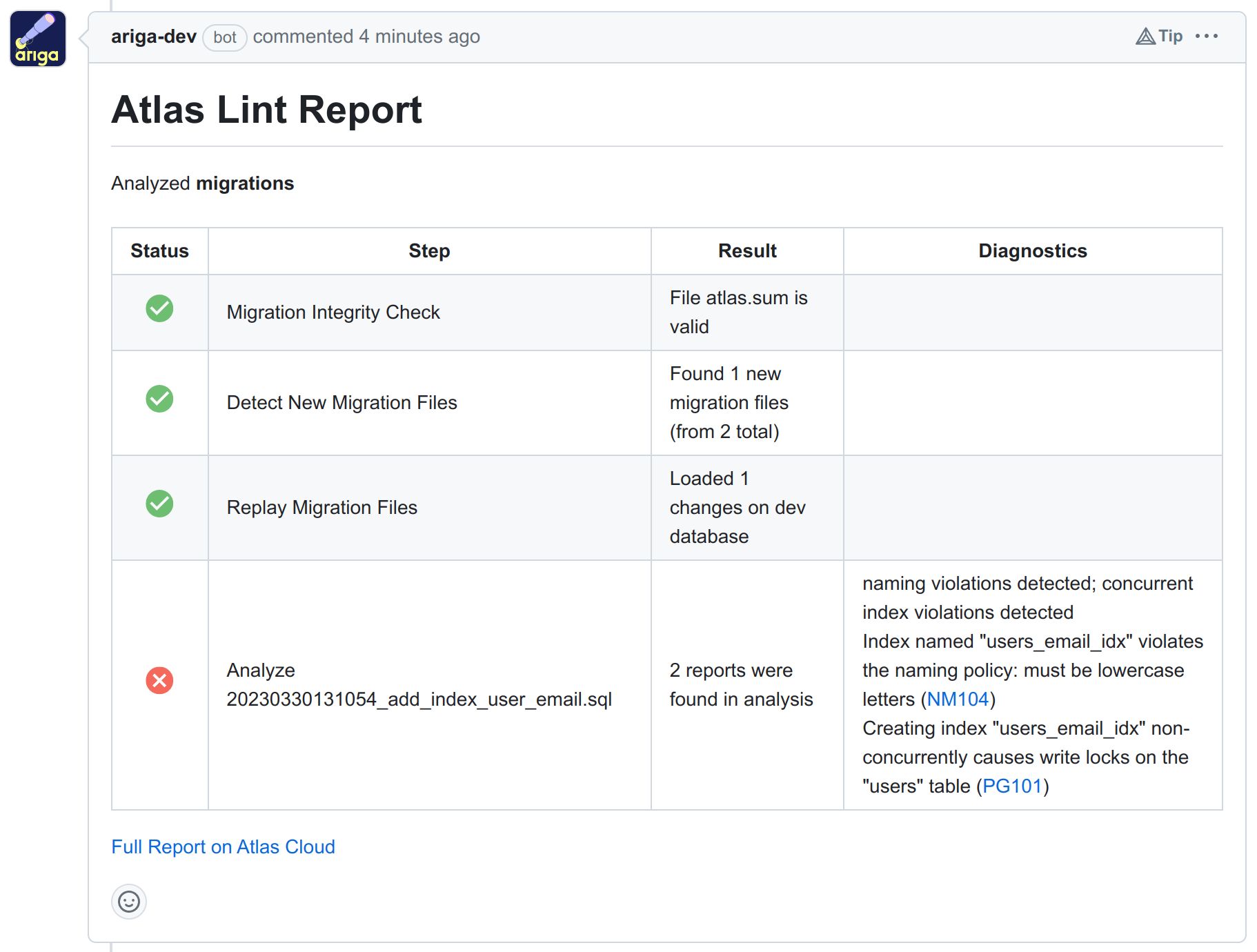
Wonderful! As you can see, Atlas Cloud found the two issues with this simple statement. Since the Concurrent Index Analyzer is configured to error on violations, merging the PR is blocked (if you have this policy set on GitHub).
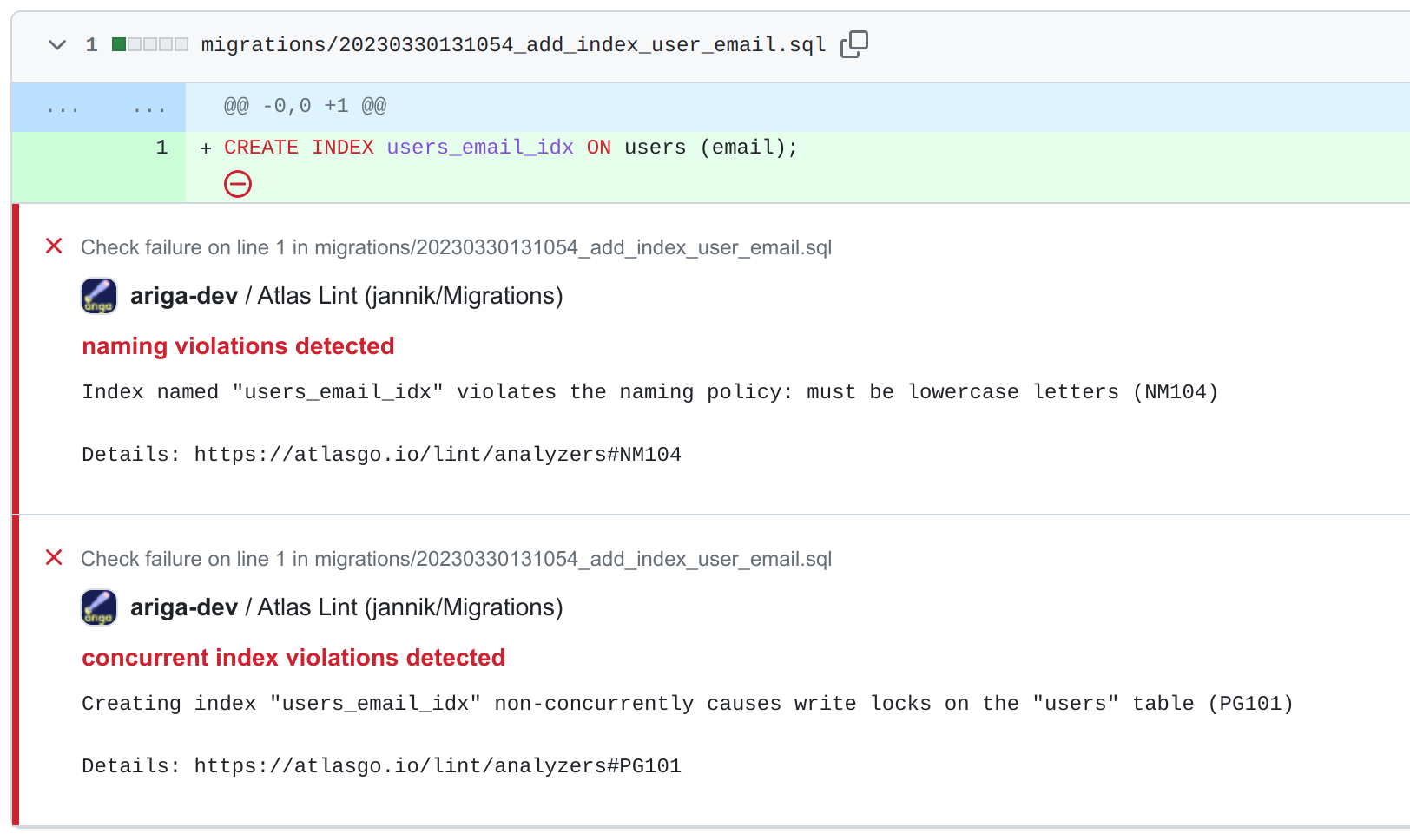
In addition to the comment on the Pull Request, you can find more detailed reporting in the Checks tab or have a look at the file annotations Atlas adds to your changes:
What next?
I sure hope the new analyzers will be useful to you. In the upcoming weeks, we will be rolling out several new major features that we have been working on lately, including schema drift detection, managed migration deployments, and much more. If any of these features sound interesting to you, please do not hesitate to contact us.
We would love to hear from you on our Discord server ❤️.