Atlas v0.32: Ask AI, SQL Imports, and More

Hey everyone!
It's been a few weeks since our last release, and we're excited to share today everything that's new in Atlas v0.32. This release is packed with new features, improvements and bug fixes that will make your experience with Atlas even better.
Here are the highlights of this release:
- Ask AI - Since its modest beginning, Atlas has come a long way. What started as a simple CLI tool for declarative schema management is now a full-blown platform. We know that the learning curve for new users can be steep, which is why we are introducing new AI-powered features to help you get started with Atlas.
- SQL Importing - As projects grow, teams often want to split their schema definition across multiple files. Because SQL definitions are imperative and rely on the order of statements, splitting them can be challenging. With the new importing feature its easy to break large SQL schema definitions into smaller parts while keeping them correct and ordered.
- Improved Ent Loader - Users of the popular Ent ORM can use the
ent://URL scheme to load their schema into Atlas. We have added support for multi-schema migrations, composite schemas, and Ent'sglobalidfeature. - SQL Server Improvements - We have made several improvements to the SQL Server support in Atlas, including support for Full Text Search Index and Temporal Tables.
- PostgreSQL Improvements - We have added support for defining Foreign Servers and Unlogged Tables in PostgreSQL.
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
Ask AI
Atlas has always been about making schema management easier for developers. We know that the learning curve for new users can be steep, which is why we are introducing new AI-powered features to help you get started with Atlas.
Ask the Docs
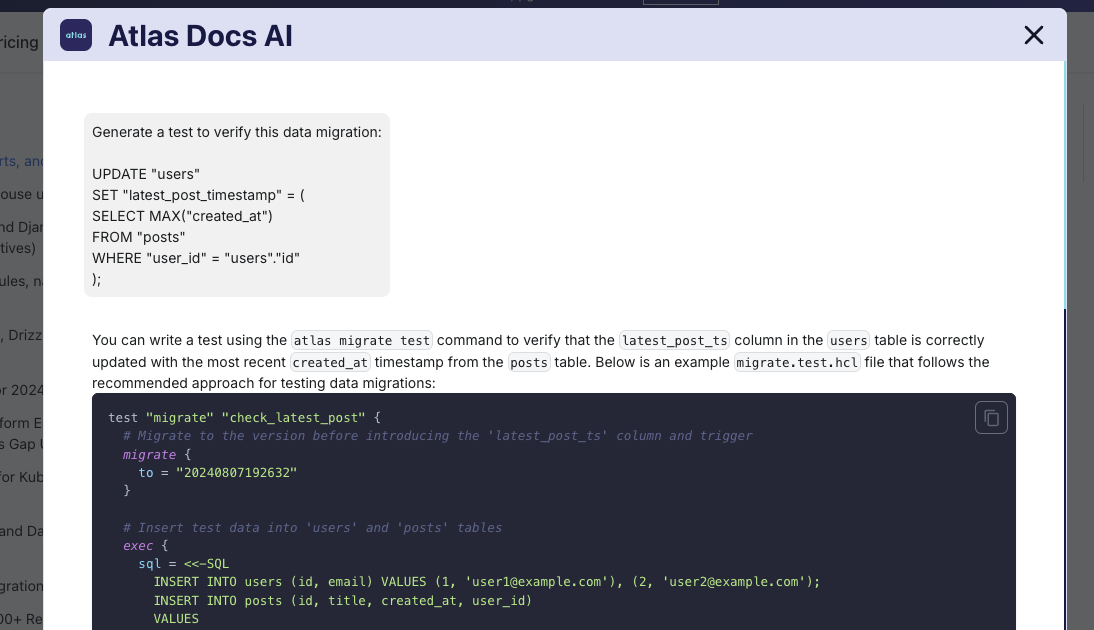
As you may have noticed, we recently added an "Ask AI" button to the top navigation bar. When clicking on it users can utilize a familiar chat-based interface to ask questions about Atlas. The answers are generated by an AI assistant that has access to the entire Atlas documentation.
The feature is still in its early stages, so we would appreciate if you could leave us feedback about any improvements we could make via the built-in feedback buttons or on our Discord server.
Ask the CLI
To help you stay in the flow while using the CLI, we have added a new command: atlas ask. Use this command whenever
you encounter an error in the CLI. The AI assistant will analyze the error message and attempt to provide a solution.
For example suppose you encounter an error like this:
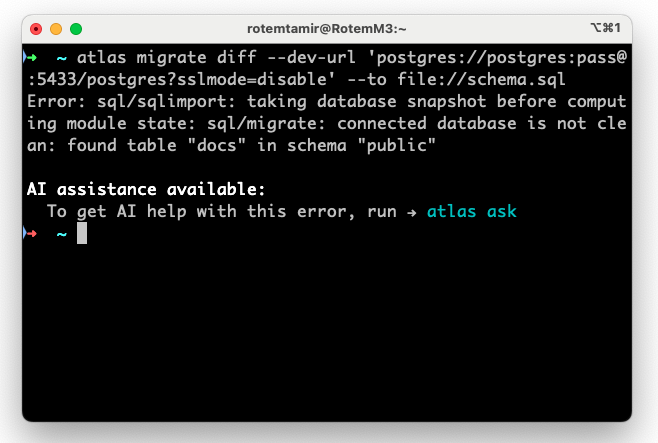
You can run atlas ask and the AI assistant will provide you with a solution:
You attempted to generate a migration using the atlas migrate diff command
with --dev-url pointing to a PostgreSQL database. However, the process failed
with the error:
sql/sqlimport: taking database snapshot before computing module state:
sql/migrate: connected database is not clean: found table "docs" in schema
"public"
### Why This Happens
The atlas migrate diff command requires the dev-database (specified by --dev-url)
to be a temporary, empty database. Atlas uses this dev-database to compute schema differences.
Your error suggests that the database you specified with --dev-url is not empty but contains
the table docs , which is causing Atlas to stop execution.
### How to Fix It
< redacted ... >
SQL Imports
As projects grow, teams often want to split their schema definition across multiple files. Because SQL definitions are imperative and rely on the order of statements, splitting them can be challenging. To enable teams to logically split their schema definitions into smaller parts while keeping them correct and ordered, we have added a new importing feature.
Suppose you are maintaining an ecommerce platform where your database schema is split into two logical schemas: one for
tracking customer and order data named crm and another for tracking back-office operations named backoffice. The
schemas are largely separate, however they share some common logic such as domain types.
Using the new importing feature, you can create a project structure like this:
.
├── backoffice
│ └── tables.sql
├── common.sql
├── crm
│ └── tables.sql
└── main.sql
Common objects can reside in the common.sql file:
CREATE SCHEMA common;
CREATE DOMAIN common.person_id AS VARCHAR
CHECK (VALUE ~* '^[A-Za-z0-9_]{6,20}$');
This file defines a username domain type, enforcing a basic format of letters, numbers, and underscores
with a length of 6-20 characters.
Then, for each schema, you can define the schema-specific objects in separate files, but note how we use
atlas:import to tell Atlas that they depend on the common.sql file:
-- atlas:import ../common.sql
CREATE SCHEMA crm;
CREATE TABLE crm.customers
(
id serial PRIMARY KEY,
full_name varchar NOT NULL,
username common.person_id UNIQUE NOT NULL
);
This file defines the customers table for tracking customer data and uses the username domain which is defined in
common.sql. Next, we define the employees table for tracking employee data in the backoffice schema:
-- atlas:import ../common.sql
CREATE SCHEMA backoffice;
CREATE TABLE backoffice.employees
(
id serial PRIMARY KEY,
full_name text NOT NULL,
position text NOT NULL,
username common.person_id UNIQUE NOT NULL
);
Finally, we create a main.sql that stitches the schemas together:
-- atlas:import backoffice/
-- atlas:import crm/
We can now use the main.sql file as the entry point for our schema definition in our Atlas project:
env {
src = "file://main.sql"
dev = "docker://postgres/17/dev"
name = atlas.env
}
If we apply this schema to a PostgreSQL database, Atlas will properly order the schema definitions using topological sort to ensure semantic correctness:
atlas schema apply --env local
Atlas computes the plan and asks for confirmation before applying the changes:
Planning migration statements (6 in total):
-- add new schema named "backoffice":
-> CREATE SCHEMA "backoffice";
-- add new schema named "common":
-> CREATE SCHEMA "common";
-- add new schema named "crm":
-> CREATE SCHEMA "crm";
-- create domain type "person_id":
-> CREATE DOMAIN "common"."person_id" AS character varying CONSTRAINT "person_id_check" CHECK ((VALUE)::text ~* '^[A-Za-z0-9_]{6,20}$'::text);
-- create "employees" table:
-> CREATE TABLE "backoffice"."employees" (
"id" serial NOT NULL,
"full_name" text NOT NULL,
"position" text NOT NULL,
"username" "common"."person_id" NOT NULL,
PRIMARY KEY ("id"),
CONSTRAINT "employees_username_key" UNIQUE ("username")
);
-- create "customers" table:
-> CREATE TABLE "crm"."customers" (
"id" serial NOT NULL,
"full_name" character varying NOT NULL,
"username" "common"."person_id" NOT NULL,
PRIMARY KEY ("id"),
CONSTRAINT "customers_username_key" UNIQUE ("username")
);
-------------------------------------------
Analyzing planned statements (6 in total):
-- no diagnostics found
-------------------------
-- 96.561ms
-- 6 schema changes
-------------------------------------------
? Approve or abort the plan:
▸ Approve and apply
Abort
Notice a few interesting things:
- The
common.sqlfile is imported only once, even though it is imported by bothcrm/tables.sqlandbackoffice/tables.sql. - The schema definitions are ordered correctly, with the
commonschema being created first, followed by thecrmandbackofficeschemas. - We did not need to think about the order of the statements in our project, as Atlas took care of that for us.
We hope this new feature will make it easier for you to manage large schema definitions in Atlas.
Ent Loader
Up until this release, the ent:// URL scheme, used to load Ent projects into Atlas, could not be
used within a composite schema or multi-schema setup if globally unique IDs were enabled.
The Ent project recently added ent schema command, which means that Ent now fully supports the Atlas External Schema
spec and thus the ent:// URL can now be used without limitations. For example:
data "composite_schema" "ent_with_triggers" {
schema "ent" {
url = "ent://entschema?globalid=static"
}
# Some triggers to be used with ent.
schema "ent" {
url = "file://triggers.my.hcl"
}
}
env {
name = atlas.env
src = data.composite_schema.ent_with_triggers.url
dev = "docker://mysql/8/ent"
migration {
dir = "file://ent/migrate/migrations"
}
}
With the recent changes, you can now use the ent:// URL scheme in a composite schema, multi-schema setup even with
globally unique IDs enabled.
SQL Server
We have made several improvements to the SQL Server support in Atlas, including support for Full Text Search Index and Temporal Tables. Full-Text Index Search in SQL Server allows efficient querying of large text-based data using an indexed, tokenized search mechanism. To create a Full-Text Index in SQL Server, you can use the following syntax:
table "t1" {
schema = schema.dbo
column "c1" {
null = false
type = int
}
column "c2" {
null = true
type = varbinary(-1)
}
column "c3" {
null = true
type = varchar(3)
}
column "c4" {
null = true
type = image
}
column "c5" {
null = true
type = varchar(3)
}
primary_key {
columns = [column.c1]
}
index "idx" {
unique = true
columns = [column.c1]
nonclustered = true
}
fulltext {
unique_key = index.idx
filegroup = "PRIMARY"
catalog = "FT_CD"
on {
column = column.c2
type = column.c3
language = "English"
}
on {
column = column.c4
type = column.c5
language = "English"
}
}
}
schema "dbo" {
}
In this example, the t1 table is defined with a fulltext block that specifies the columns to be indexed and the
language to use.
For more examples, consider the Atlas Docs.
Temporal Tables
SQL Server Temporal Tables automatically track historical changes by maintaining a system-versioned table (current data)
and a history table (previous versions with timestamps). This allows for time travel queries (FOR SYSTEM_TIME), making
it useful for auditing, data recovery, and point-in-time analysis. Here's an example of how to define a Temporal Table
using Atlas HCL:
schema "dbo" {}
table "t1" {
schema = schema.dbo
column "c1" {
type = int
null = false
}
column "c2" {
type = money
null = false
}
column "c3" {
type = datetime2(7)
null = false
generated_always {
as = ROW_START
}
}
column "c4" {
type = datetime2(7)
null = false
generated_always {
as = ROW_END
}
}
primary_key {
on {
column = column.c1
desc = true
}
}
period "system_time" {
type = SYSTEM_TIME
start = column.c3
end = column.c4
}
system_versioned {
history_table = "dbo.t1_History"
retention = 3
retention_unit = MONTH
}
}
In this example, the t1 table is defined with a system_time period and a system_versioned history table.
The system_versioned block specifies the history table name, retention period, and retention unit.
PostgreSQL
Following requests from the Atlas community, we have added support for more lesser known features in PostgreSQL. Here they are:
Foreign Servers
Foreign Servers in PostgreSQL allow you to access data from other databases or servers. They are used in conjunction with Foreign Data Wrappers (FDWs) to provide a unified view of data from multiple sources. Here's an example of how to define a Foreign Server using Atlas HCL:
extension "postgres_fdw" {
schema = schema.public
}
server "test_server" {
fdw = extension.postgres_fdw
comment = "test server"
options = {
dbname = "postgres"
host = "localhost"
port = "5432"
}
}
This example defines a Foreign Server named test_server that connects to a PostgreSQL database running on localhost
on port 5432.
Unlogged Tables
In PostgreSQL, unlogged tables are a special type of table that do not write data to the WAL (Write-Ahead Log), making them faster but less durable. To use unlogged tables in Atlas, you can define them like this:
table "t1" {
schema = schema.public
unlogged = true
column "a" {
null = false
type = integer
}
primary_key {
columns = [column.a]
}
}
WITH NO DATA Diff Policy
When creating a materialized view in PostgreSQL, you can use the WITH NO DATA clause to create the view without
populating it with data. This can be useful when you want to create the view first and populate it later. To use this
feature in Atlas, you can utilize the with_no_data option in the diff block like this:
diff {
materialized {
with_no_data = var.with_no_data
}
}
Wrapping Up
We hope you enjoy the new features and improvements. As always, we would love to hear your feedback and suggestions on our Discord server.