Announcing Automatic Migrations for Hibernate Users

You can now import the desired database schema from your Hibernate project into Atlas, and use it to automatically plan migrations for you.
Introduction
Hibernate-ORM is one of the most popular ORMs for Java, so much so that parts of it have evolved into the JPA standard and the Jakarta APIs.
Today, we are excited to announce that Atlas now supports loading and managing Hibernate schemas.
Atlas is a modern tool for managing your database schema. It allows you to inspect, plan, lint and apply schema changes to your database. It is designed to be used by developers, DBAs and DevOps engineers alike.
By using Atlas, Hibernate users can now enjoy these benefits:
- A declarative migration flow - Atlas can operate like a "Terraform for databases", where
by running
atlas schema applythe application schema is applied on a target database. - Automatic schema migration planning - Alternatively, Atlas can operate using a more traditional versioned migration flow. However, contrary to most tools, Atlas will automatically analyze the diff between the migration directory and the current application data model, and will produce correct and safe SQL migration files.
- CI for schema changes - Atlas can be used during CI to make sure you never merge a pull request that will break your database schema.
- Modern CD integrations - Atlas integrates seamlessly with modern deployment tools such as Kubernetes, Terraform, Helm, Flux, and ArgoCD. This allows you to deploy changes to your database schema as part of your existing deployment pipelines.
- Visualization - Atlas users can create beautiful, shareable ERDs of their application data model with a single command.
- .. and much more (read more about Atlas features).
Integrating Atlas into your Hibernate project
Hibernate ships with an automatic schema management tool called hbm2ddl.
Similarly to Atlas, this tool can inspect a target database and automatically migrate the schema to the desired one. However, the Hibernate team has been advising for years not to use this tool in production:
Although the automatic schema generation is very useful for testing and prototyping purposes, in a production environment, it’s much more flexible to manage the schema using incremental migration scripts.
This is where Atlas comes in. Atlas can read Hibernate schema and plan database schema migrations.
How does it work?
Atlas compares two database schema states and plans a migration to get from ones state to the other. The database schema can be read directly from Hibernate, a migration directory, a database connection, or another ORM.
To read the Hibernate schema, Atlas utilizes the concept of an external_schema datasource.
Demo Time
For this demo, we are going to use Gradle, PostgreSQL and this example project.
Installation
If you haven't already, install the latest version of Atlas:
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
Add the hibernate-provider to your project via Gradle or Maven:
- Gradle Kotlin
- Gradle Groovy
- Maven
plugins {
id("io.atlasgo.hibernate-provider-gradle-plugin") version "0.1"
}
To check the installation, run:
./gradlew help --task schema
plugins {
id "io.atlasgo.hibernate-provider-gradle-plugin" version "0.1"
}
To check the installation, run:
./gradlew help --task schema
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>io.atlasgo</groupId>
<artifactId>hibernate-provider-maven-plugin</artifactId>
<version>0.1</version>
</plugin>
</plugins>
</pluginManagement>
</build>
To check the installation, run
mvn help:describe -Dplugin=hibernate-provider -Dgoal=schema
Configuration
The plugin adds a configurable Gradle task (or a Maven goal) that prints the Hibernate schema without requiring a database connection.
However, the task needs to be configured with the database dialect. We can do this by creating a schema-export.properties file in the
resource directory. For example, for MySQL / PostgreSQL:
- MySQL
- PostgreSQL
jakarta.persistence.database-product-name=MySQL
jakarta.persistence.database-major-version=8
jakarta.persistence.database-product-name=PostgreSQL
jakarta.persistence.database-major-version=15
Lastly, we need to configure Atlas to use this configuration by creating an atlas.hcl file
and adding the definition of the Hibernate schema:
- Gradle
- Maven
data "external_schema" "hibernate" {
program = [
"./gradlew",
"-q",
"schema",
"--properties", "schema-export.properties"
]
}
data "external_schema" "hibernate" {
program = [
"./mvn",
"-q",
"hibernate-provider:schema",
"-Dproperties", "schema-export.properties"
]
}
And the Atlas configuration:
- MySQL
- PostgreSQL
env "hibernate" {
src = data.external_schema.hibernate.url
dev = "docker://mysql/8/dev"
migration {
dir = "file://migrations"
}
format {
migrate {
diff = "{{ sql . \" \" }}"
}
}
}
env "hibernate" {
src = data.external_schema.hibernate.url
dev = "docker://postgres/15/dev?search_path=public"
migration {
dir = "file://migrations"
}
format {
migrate {
diff = "{{ sql . \" \" }}"
}
}
}
Running Atlas
We should now be able to view our schema using Atlas:
atlas schema inspect -w --env hibernate --url env://src
The -w flag allows us to inspect the schema in atlas cloud:
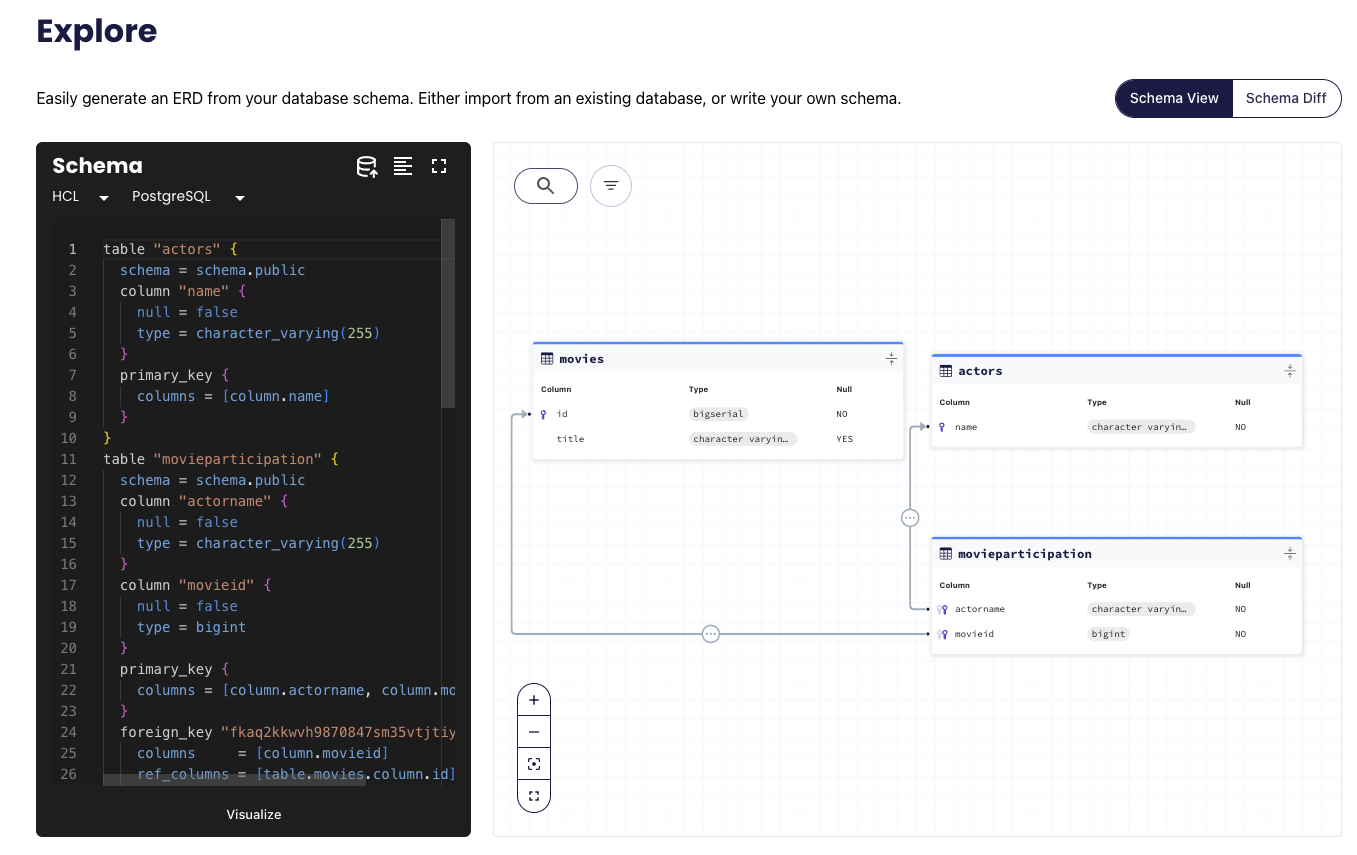
Atlas has many more features we can explore, let's create a migration directory from our schema:
atlas migrate diff --env hibernate
By running atlas migrate diff, Atlas compares the state of our Hibernate schema and the state of the schema in the migration directory.
Atlas sees that the migration directory does not exist and initializes it with the current Hibernate schema.
Observe the migration directory, it should contain similar files:
- migrations/20231211114848.sql
- migrations/atlas.sum
-- Create "movies" table
-- Create "movies" table
CREATE TABLE "movies" (
"id" bigserial NOT NULL,
"numberinseries" integer NULL,
"title" character varying(255) NULL,
PRIMARY KEY ("id")
);
-- Create "actors" table
CREATE TABLE "actors" (
"name" character varying(255) NOT NULL,
PRIMARY KEY ("name")
);
-- Create "movieparticipation" table
CREATE TABLE "movieparticipation" (
"actorname" character varying(255) NOT NULL,
"movieid" bigint NOT NULL,
PRIMARY KEY ("actorname", "movieid"),
CONSTRAINT "fkaq2kkwvh9870847sm35vtjtiy" FOREIGN KEY ("movieid") REFERENCES "movies" ("id") ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT "fktm8fbwa577lnbvwdjegwxvget" FOREIGN KEY ("actorname") REFERENCES "actors" ("name") ON UPDATE NO ACTION ON DELETE NO ACTION
);
h1:Ezh6r7A0pU4XS7PztE87h+aq5PoGGVTd6kaprtpXxas=
20231211114848.sql h1:9ECs2QsjHE8S4PxXxFcoPYaOVUWRjpxHuF8MGFRd3dE=
Atlas uses the atlas.sum file to protect against conflicting schema changes, you can read about it here.
Currently, Atlas does not support using generated fields that require data initialization such as GenerationType.SEQUENCE, GenerationType.TABLE, and Generation.AUTO.
If needed, you can still export the schema using the flag --enable-table-generators (or -Denable-table-generators using Maven). When applying the schema to your database, you will need
to make sure to apply the ignored statements (using atlas migrate --env hibernate diff --edit). See more information on manual migrations here
For example, if you are adding GenerationType.SEQUENCE to the Event entity, you will need to add insert statements to your generated migration file:
diff --git a/migrations/20231210140844.sql b/examples/with_local_plugin_repository/migrations/20231210140844.sql
index ad80a64..5955834 100644
--- a/migrations/20231210140844.sql
+++ b/migrations/20231210140844.sql
@@ -4,3 +4,6 @@ CREATE TABLE `Event` (`id` bigint NOT NULL AUTO_INCREMENT, `title` varchar(255)
-- Create "Event_SEQ" table
CREATE TABLE `Event_SEQ` (`next_val` bigint NULL) CHARSET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
+ -- Initialize "Event_SEQ" table
+ insert into Event_SEQ values ( 1 );
Testing these changes can be done by running the application with a local database and creating the entity. To apply the migration directory
to the local database, use atlas migrate apply.
Testing the migrations
Now that our migration directory is ready, let's see how to apply it to a target database. Let's start a local PostgreSQL instance:
docker run -it --rm --name mypostgres -p 5432:5432 -e 'POSTGRES_PASSWORD=password' postgres
Next, let's apply our migrations to the database:
atlas migrate apply --env hibernate --url 'postgres://postgres:password@localhost:5432/?search_path=public&sslmode=disable'
Atlas provides details on the applied migrations:
Migrating to version 20231211121102 (1 migrations in total):
-- migrating version 20231211121102
-> CREATE TABLE "movies" (
"id" bigserial NOT NULL,
"numberinseries" integer NULL,
"title" character varying(255) NULL,
PRIMARY KEY ("id")
);
-> CREATE TABLE "actors" (
"name" character varying(255) NOT NULL,
PRIMARY KEY ("name")
);
-> CREATE TABLE "movieparticipation" (
"actorname" character varying(255) NOT NULL,
"movieid" bigint NOT NULL,
PRIMARY KEY ("actorname", "movieid"),
CONSTRAINT "fkaq2kkwvh9870847sm35vtjtiy" FOREIGN KEY ("movieid") REFERENCES "movies" ("id") ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT "fktm8fbwa577lnbvwdjegwxvget" FOREIGN KEY ("actorname") REFERENCES "actors" ("name") ON UPDATE NO ACTION ON DELETE NO ACTION
);
-- ok (9.282079ms)
-------------------------
-- 54.100203ms
-- 1 migrations
-- 3 sql statements
To confirm the migrations were applied, we can use Atlas to inspect the database. Run the following command:
atlas schema inspect -w --env hibernate --url 'postgres://postgres:password@localhost:5432/?search_path=public&sslmode=disable'
Making changes with confidence
Atlas ships with a static code analysis engine that can detect risky schema changes during development or Continuous Integration.
This functionality is exposed to users via the migrate lint command.
Let's demonstrate this capability with an example.
Suppose we make the following change:
--- a/src/main/java/org/example/Movie.java
+++ b/src/main/java/org/example/Movie.java
@@ -10,13 +10,10 @@ public class Movie {
Movie(String title, Integer numberInSeries) {
this.title = title;
- this.numberInSeries = numberInSeries;
}
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
public Long id;
public String title;
-
- public Integer numberInSeries;
}
By removing an attribute from the Movie model, we are removing a column from the database schema.
Let's see how Atlas handles this change. Run atlas migrate diff --env hibernate, and observe the new file in the migration directory:
-- Modify "movies" table
ALTER TABLE "movies" DROP COLUMN "numberinseries";
While this change may be desired, it is an irreversible operation that should be done with caution. Atlas can help us avoid dangerous schema changes by linting the migration directory and not allowing such a change to get merged.
Running the following command, we can see that Atlas will warn us about a destructive change to the database:
atlas migrate lint --env hibernate --latest 1
20231211124321.sql: destructive changes detected:
L2: Dropping non-virtual column "numberinseries"
Running migrate lint locally during development can be very useful, but linting becomes much more powerful when you
integrate into your Continuous Integration pipeline.
Atlas offers a set of Github Actions designed to make setting this up a breeze.
Conclusion
In this post, we have presented how Hibernate projects can use Atlas to automatically plan, lint and apply schema migrations based only on their data model.
If you want to explore more configuration options or dive deeper into how this works, please take a look at this repository.
How can we make Atlas better?
We would love to hear from you on our Discord server ❤️.