Announcing Atlas v0.9.0: SQL as a First-Class Citizen

For a long time, one of the most common feature requests we've been getting from our users is the ability to manage their desired "schema state" using SQL. This is understandable, using Atlas DDL (HCL) can feel unfamiliar to some users, especially those who have never worked with Terraform before. For this reason, we're excited to announce the release of Atlas v0.9.0, which now fully supports SQL.
Schema as Code (SaC)
Atlas applies the common IaC concept of declarative resource management to database schemas. With Atlas, users do not need to plan schema changes themselves. Instead of figuring out the correct SQL statements to update their database schemas, users provide to Atlas the schema definition that describe their desired state and Atlas generates a migration plan to move from the current state to the desired state defined by the schema.
Starting from v0.9.0, users can use SQL schema files (or a directory) containing CREATE and ALTER statements
to describe their desired state. To demonstrate this, let's use this schema example with a single users table:
-- create table "users
CREATE TABLE users(
id int NOT NULL,
name varchar(100) NULL,
PRIMARY KEY(id)
);
Given this schema file, Atlas offers two workflows to update databases:
- Declarative: Similar to Terraform, Atlas compares the current state of the database schema with the desired state defined by the SQL schema, and generates a migration plan to reach that state.
- Versioned: Atlas compares the current state defined by the
migrationsdirectory to the desired state defined by the SQL schema, and writes a new migration script to the directory to update the database schema to the desired state.
In this blog post, we'll focus on explaining how SQL schemas can be used with the declarative workflow. For the sake of simplicity, let's assume we have an empty database that we want to apply the schema above to:
- MySQL
- MariaDB
- PostgreSQL
- SQLite
atlas schema apply \
--url "mysql://root:pass@localhost:3306/example" \
--to "file://schema.sql" \
--dev-url "docker://mysql/8/example"
atlas schema apply \
--url "maria://root:pass@:3306/example" \
--to "file://schema.sql" \
--dev-url "docker://maria/latest/example"
atlas schema apply \
--url "postgres://postgres:pass@localhost:5432/database?search_path=public&sslmode=disable" \
--to "file://schema.sql" \
--dev-url "docker://postgres/15"
atlas schema apply \
--url "sqlite://file.db" \
--to "file://schema.sql" \
--dev-url "sqlite://file?mode=memory"
--url- the database URL to apply the schema to.--to- URLs describe the desired state: SQL or HCL schema definition, or a database URL.--dev-url- a URL to a Dev Database that will be used to compute the diff.
Running the command above with the --auto-approve flag will apply the following changes:
-- Planned Changes:
-- Create "users" table
CREATE TABLE `users` (`id` int NOT NULL, `name` varchar NULL, PRIMARY KEY (`id`));
Hooray! We have successfully created the users table defined in our schema file. Let's inspect our database and ensure
its schema was actually updated by the command above:
- MySQL
- MariaDB
- PostgreSQL
- SQLite
atlas schema inspect \
--url "mysql://root:pass@localhost:3306/example" \
--format "{{ sql . }}"
atlas schema inspect \
--url "maria://root:pass@:3306/example" \
--format "{{ sql . }}"
atlas schema inspect \
--url "postgres://postgres:pass@localhost:5432/database?search_path=public&sslmode=disable" \
--format "{{ sql . }}"
atlas schema inspect \
--url "sqlite://file.db" \
--format "{{ sql . }}"
Excellent! As you can see, our database schema has been updated:
-- create "users" table
CREATE TABLE `users` (`id` int NOT NULL, `name` varchar NULL, PRIMARY KEY (`id`));
Now let's make our schema more interesting by adding a column to the users table and creating a blog_posts table
with a foreign key that references users:
-- create table "users
CREATE TABLE users(
id int NOT NULL,
name varchar(100) NULL,
email varchar(50) NULL,
PRIMARY KEY(id)
);
-- create table "blog_posts"
CREATE TABLE blog_posts(
id int NOT NULL,
title varchar(100) NULL,
body text NULL,
author_id int NULL,
PRIMARY KEY(id),
CONSTRAINT author_fk FOREIGN KEY(author_id) REFERENCES users(id)
);
Next, executing atlas schema apply again will update the database schema with the following changes:
-- Planned Changes:
-- Add column "email" to table: "users"
ALTER TABLE `users` ADD COLUMN `email` varchar NULL;
-- Create "blog_posts" table
CREATE TABLE `blog_posts` (`title` varchar NULL, `body` text NULL, `author_id` int NULL, `id` int NOT NULL, PRIMARY KEY (`id`), CONSTRAINT `author_fk` FOREIGN KEY (`author_id`) REFERENCES `users` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION);
Boom! Atlas automatically calculates the difference between the current state of our database and the desired state defined by our schema file, and generates the necessary changes to migrate the database to the new state. We don't need to specify each individual migration – we simply tell Atlas what state we want the database to be in, and it handles the rest.
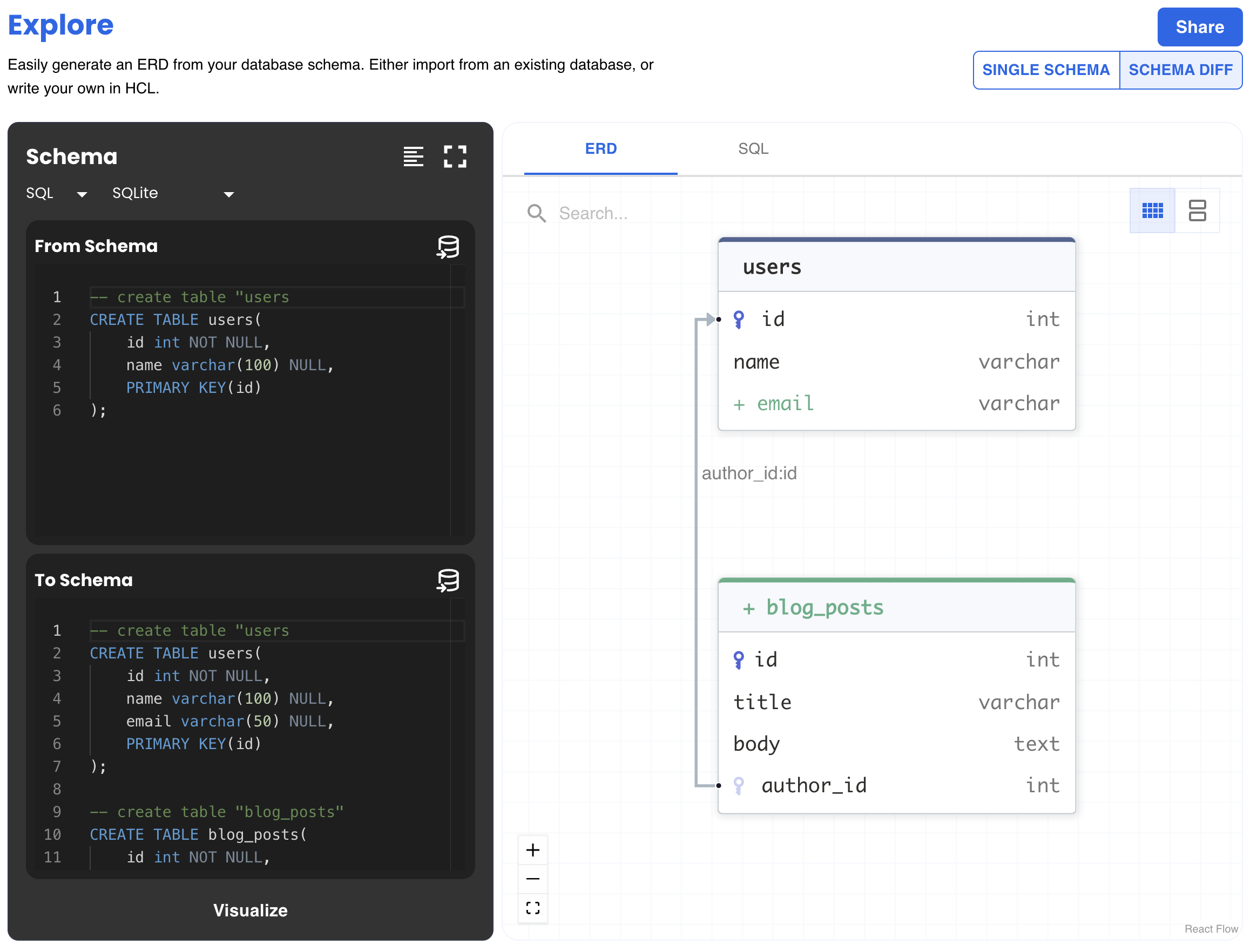
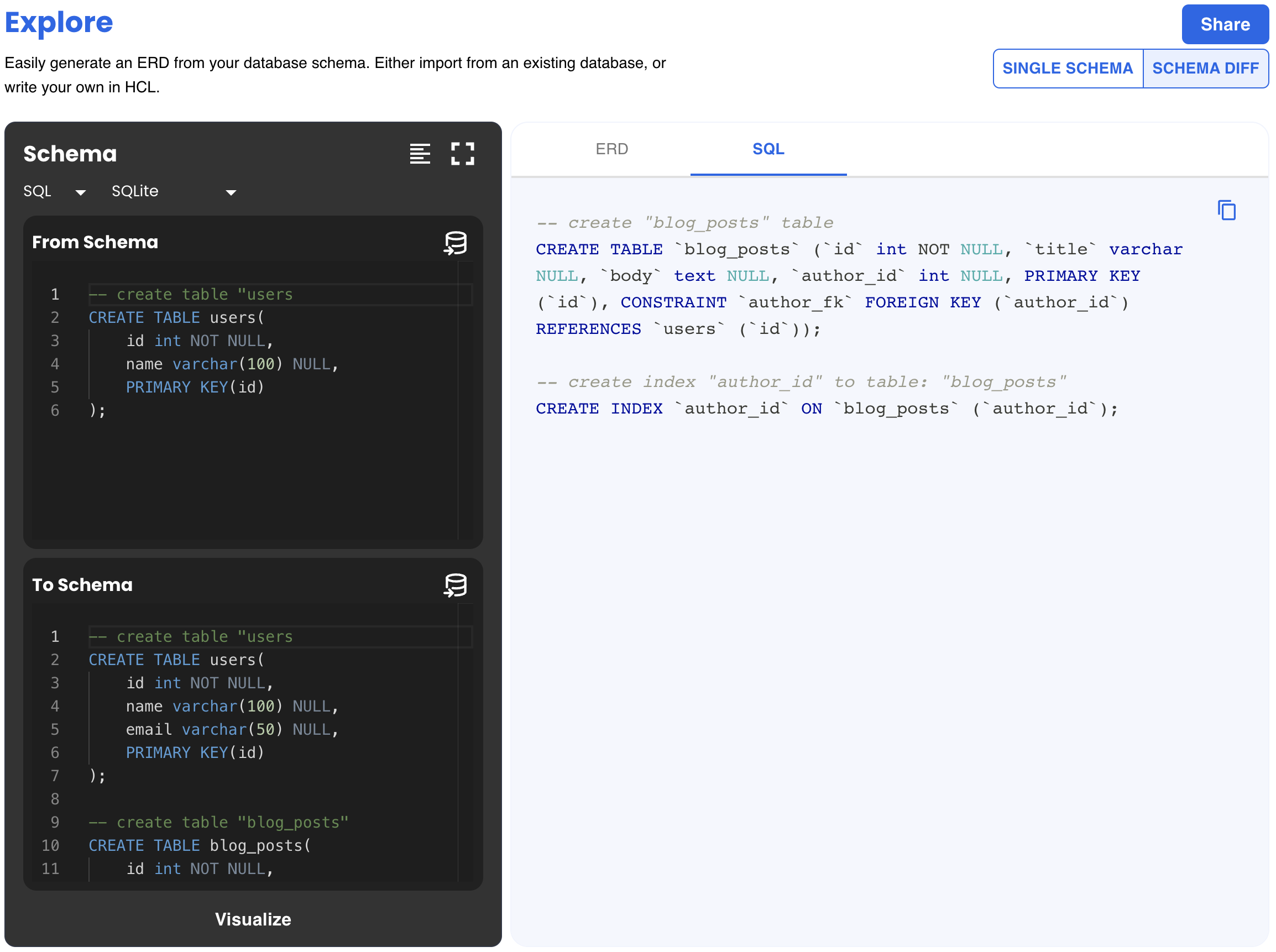
To see a full description of this generated migration plan, check out this diagram example in Atlas public playground:
Diff ERD
Diff SQL
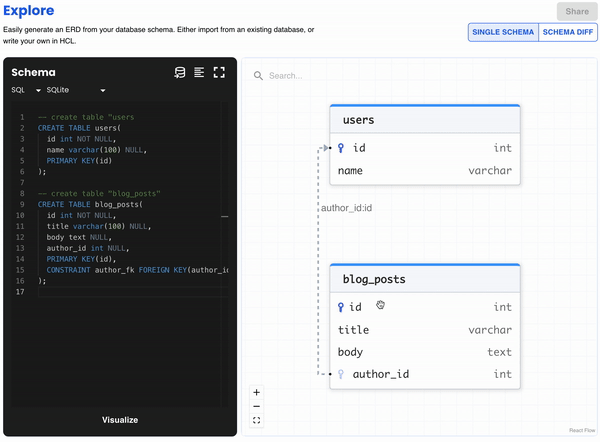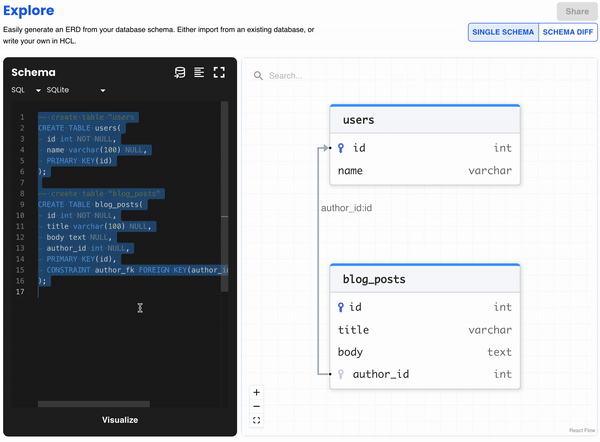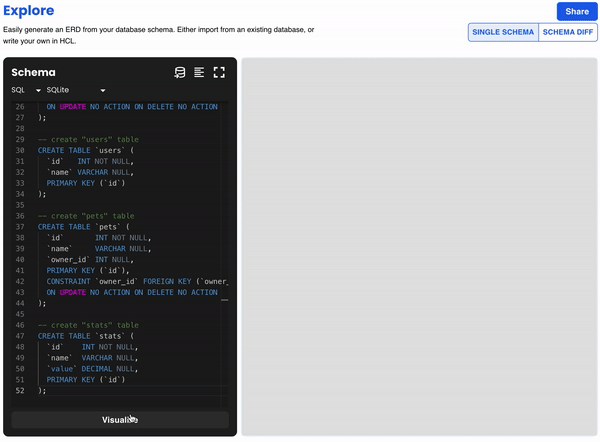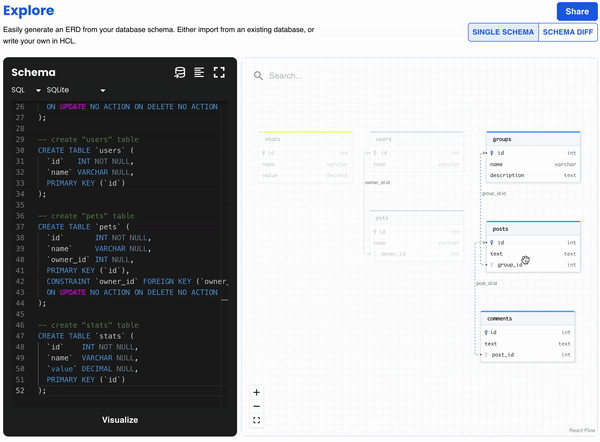
Atlas Playground
As part of this version, we have released the Atlas playground where users can visualize their database schemas in an interactive way. Simply provide an SQL or HCL schema, or import one from an existing database, and in return get an ERD visualizing their entire data model.
Users can also compare between two schemas with the Schema Diff button, and get the SQL statements necessary to migrate from one schema to the other - give it try!
A big thanks to @solomonme, @ronenlu and @masseelch for contributing this feature to Atlas!
Schema Loaders
What's next? In the near future, we plan to add an infrastructure for loading schemas from external sources. This will enable ORM maintainers to integrate with Atlas and provide their schema definitions as Atlas schemas. As as result, they can utilize the Atlas engine to diff schemas, plan and lint migrations, execute them on the databases, and more.
The first ORM to integrate with Atlas will be Ent. Using this integration, Ent users will be able to generate Atlas schemas or migrations for their Ent projects with a single command:
atlas migrate diff create_users \
--dir "file://migrations" \
--to "ent://path/to/schema" \
--dev-url "docker://<driver-name>"
Would you like to see other ORMs integrated with Atlas? Please, join our Discord server and let me know.
What next?
Have questions or feedback? Feel free to reach out on our Discord server.