Atlas v0.37: Databricks in Beta, ClickHouse Clusters, Migration Rules, and More

Hey everyone!
Some time has passed since our previous release, and we're very excited to bring you another large batch of exciting additions in Atlas v0.37.
- Databricks Driver Beta - Atlas now supports managing Databricks databases in beta.
- ClickHouse Support Additions - We've expanded the support for ClickHouse to include clusters, user-defined functions, table projections, table partitions, and experiment types.
- SQL Server Support Additions - Our support for SQL Server has been extended to include SQL Server 2008, 2012, 2014, and 2016.
- Broader Scope for Linting Analyzers - Atlas now
supports configuring analyzers to follow object deprecation workflows, enforce checks, block
nolintusage, and allow or block specific SQL statements in migrations. - Custom Migration Rules - Similar to custom schema rules, Atlas Pro users can now write rules for schema changes in their migrations.
- Pre-Execution Checks for Versioned Migrations -
Added support for policy rules that run before migration execution. Teams can now allow or deny migrations based on conditions such as the
number of pending files or specific SQL statements (e.g., blocking
CREATE INDEXduring peak hours). - Cloud Databases as a Data Source - Users
can now dynamically retrieve the migration status of different environments using the
cloud_databasesdata source. - Support for Hashicorp Vault - Atlas Pro users can now retrieve database credentials stored in Hashicorp Vault.
- Discover Database Instances for Schema Monitoring - Use the Atlas Agent to discover all database instances in your environment automatically in order to monitor them in Atlas Cloud.
- Protected Flows by Default - Atlas Cloud users can configure their settings to enable protected flows on all new projects.
Databricks Driver Beta
A core goal of Atlas is to deliver a unified experience for managing database schemas across different database platforms. We've recently been targeting this goal with the additions of beta support for Snowflake, Oracle, and Google Spanner. We're eager to share that Databricks has now been added to this list.
- macOS + Linux
- Docker
- Windows
To download and install the custom release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | ATLAS_FLAVOR="databricks" sh
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas:latest-extended
docker run --rm arigaio/atlas:latest-extended --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas:latest-extended migrate apply \
--url "oracle://PDBADMIN:Pssw0rd0995@localhost:1521/FREEPDB1"
Download the custom release and move the atlas binary to a file location on your system PATH.
Getting Started with Databricks
This quick guide will help you connect Atlas to your Databricks account and inspect your schema in just a few steps.
For a more detailed walkthrough, check out our Databricks guide.
Databricks support is an Atlas Pro feature. You can try out Atlas Pro for free by signing up or running:
atlas login
To connect Atlas to your Databricks workspace, you'll need to set up authentication using a Personal Access Token (PAT):
- Log in to your Databricks workspace
- Click on your username in the top-right corner and select "User Settings"
- Go to the "Developer" tab
- Click "Manage" next to "Access tokens"
- Click "Generate new token"
- Give your token a description and set an expiration (optional)
- Copy the generated token and store it securely
Set your Databricks credentials as environment variables:
export DATABRICKS_TOKEN="your-personal-access-token"
export DATABRICKS_HOST="dbc-xxxxxxxx-xxxx.cloud.databricks.com"
export DATABRICKS_WAREHOUSE="/sql/1.0/warehouses/your-warehouse-id"
Run the following SQL commands to create a schema in your Databricks workspace:
-- Create an initial table
CREATE TABLE IF NOT EXISTS users (
id BIGINT NOT NULL,
email STRING,
display_name STRING,
created_at TIMESTAMP
);
After everything is set up, inspect your database schema with Atlas:
atlas schema inspect -u "databricks://$DATABRICKS_TOKEN@$DATABRICKS_HOST:443$DATABRICKS_WAREHOUSE"
This will print in your terminal:
table "users" {
schema = schema.default
column "id" {
null = false
type = BIGINT
}
column "email" {
null = true
type = STRING
}
column "display_name" {
null = true
type = STRING
}
column "created_at" {
null = true
type = TIMESTAMP
}
properties = {
"delta.checkpoint.writeStatsAsJson" = "false"
"delta.checkpoint.writeStatsAsStruct" = "true"
"delta.enableDeletionVectors" = "true"
"delta.feature.appendOnly" = "supported"
"delta.feature.deletionVectors" = "supported"
"delta.feature.invariants" = "supported"
"delta.minReaderVersion" = "3"
"delta.minWriterVersion" = "7"
"delta.parquet.compression.codec" = "zstd"
}
}
schema "default" {
}
ClickHouse Support Additions
We're eager to share that our ClickHouse support has recently expanded to cover more features so Atlas can better manage your ClickHouse schemas. These additions include:
Cluster Mode
Atlas now supports managing schema changes for ClickHouse clusters, but this process requires a comprehensive understanding of several key concepts. To help with the configuration, we put together a guide to help you get started.
For example, if you'd like to apply schema changes to all nodes in a cluster, you can use the ON CLUSTER clause in your
migration by adding a cluster block to your atlas.hcl configuration:
env "local" {
diff "clickhouse" {
cluster {
name = "my_cluster" # The name of your ClickHouse cluster
}
}
}
When everything is set up, the grenerated SQL migration will include the ON CLUSTER clause:
CREATE TABLE IF NOT EXISTS `my_table` ON CLUSTER `my_cluster` (...) ENGINE = MergeTree()
User-Defined Functions
ClickHouse user-defined functions (UDFs) allow users to create custom functions using SQL expressions. These functions can then be used in queries just like any built-in ClickHouse function. Atlas can now manage ClickHouse UDFs in HCL schema definitions:
function "plus_one" {
as = "(x) -> x + 1"
}
Table Projections
ClickHouse offers table projections as a tool to optimize query performance by sorting or aggregating data in a specific layout without needing to rewrite queries. Atlas can also now manage ClickHouse table projections in HCL schema definitions:
table "name" {
schema = schema.public
projection "name" {
as = "SELECT * FROM table WHERE condition"
}
projection "another" {
as = "SELECT * FROM table WHERE another_condition"
}
}
Table Partitioning
ClickHouse also offers table partitioning to organize data for data management by dividing the table's data into logical segments based on a partitioning key. Atlas now supports ClickHouse table partitioning in HCL schema definitions:
# Example of a table with partitioning by composite columns
partition {
columns = [col1, col2]
}
# Example of a table with expression-based partitioning
partition {
on {
expr = "toYYYYMMDD(date)"
}
}
# Example of a table with tuple-based
partition {
on {
column = column.col1
}
on {
expr = "toYYYYMM(date)"
}
}
Experimental Data Types
Last but certainly not least, Atlas now supports ClickHouse experimental data types, Variant and Dynamic,
in HCL schema definitions.
To enable experimental data types, you need to configure the following settings in your ClickHouse session:
SET allow_experimental_variant_type = 1;
SET allow_experimental_dynamic_type = 1;
Or via URL parameters:
clickhouse://localhost:9000?allow_experimental_variant_type=1&allow_experimental_dynamic_type=1
You can then define these data types in your schema using the following syntax:
column "variant_column" {
type = sql("Variant(Array(UInt32), String, Tuple(`a` UInt64, `b` String), UInt64)")
}
column "dynamic_column" {
type = Dynamic
}
column "dynamic_with_max_types" {
type = sql("Dynamic(max_types=10)")
}
Broadening the Scope of our Linting Analyzers
Atlas offers linting analyzers for users to check the safety of schema changes before they are applied to the target database. These analyzers include checks for destructive changes, backward-incompatible changes, non-linear changes, and more. With this release, Atlas Pro users can now configure their analyzer to allow intentional destructive changes in a deprecation workflow.
lint {
destructive {
// Allow dropping tables or columns
// that their name start with "drop_".
allow_table {
match = "drop_.+"
}
allow_column {
match = "drop_.+"
}
}
}
On the flipside, destructive changes can be considered high-risk for some teams, requiring them to be flagged even if the
--atlas:no-lint directive has been added to the migration files. In these cases, teams can now force the destructive
analyzer to always run.
lint {
destructive {
force = true
}
}
Pro users can also use the new statement analyzer to define regular expression rules to allow or deny specific SQL
statements in your migration files.
lint {
statement {
error = true
deny "delete-truncate" {
match = "(?i)(DELETE|TRUNCATE)"
}
}
}
Custom Migration Rules
Earlier this year, we introduced Custom Schema Policy, allowing users to define rules of their own to be enforced when linting. We have now expanded this capability to migrations, allowing users to define rules for their migrations that the linter can enforce.
These rules are applied to the migration files themselves, rather than the desired schema as a whole. For example, a schema
rule may enforce that all tables have a primary key, while a migration rule enforces that all ADD TABLE SQL statements in
a migration contain a primary key columm.
- Migration Rule
- Schema Rule
predicate "table" "has_primary_key" {
primary_key {
condition = self != null
}
}
rule "migrate" "added-table-has-primary-key" {
description = "Added tables must have a primary key"
add {
table {
assert {
predicate = predicate.table.has_primary_key
message = "Added table ${self.name} must have a primary key"
}
}
}
}
predicate "table" "has_primary_key" {
primary_key {
condition = self != null
}
}
rule "schema" "table-has-primary-key" {
description = "All tables must have a primary key"
table {
assert {
predicate = predicate.table.has_primary_key
message = "Table ${self.name} must have a primary key"
}
}
}
Pre-Execution Checks
When using the versioned migrations workflow, users can now define pre-execution checks
that are evaluated before Atlas begins applying migration files with the atlas migrate apply command. This allows teams to
prevent destructive or time-consuming changes.
For example, if your team is consistently creating many migration files, but applying them all at once takes a long time and drains resources, you can define the following check to ensure that no more than three migration files are applied at a time:
env "prod" {
migration {
dir = "file://migrations"
}
check "migrate_apply" {
deny "if_more_than_3_files" {
condition = length(self.planned_migration.files) > 3
message = "Cannot apply more than 3 migration files in a single run. Split them into smaller batches."
}
}
}
Cloud Databases Data Source
Data sources enable users to retrieve information from an external service or database. With Atlas v.037, users can dynamically retrieve the migration statuses of different environments directly from Atlas Cloud.
The cloud_databases data source takes two arguments: repo and env.
These correspond with the Cloud repository you're connecting to and the environment name by which to filter the databases, respectively.
It returns a list of databases that match the criteria, from which you can query the names, environment names, URLs, statuses, and current
versions of each listed database.
This data source comes in handy when promoting workflow between environments. For example, SOC2 requires that migration files must be deployed to lower environments before being applied to production. To follow this requirement, you can use the following configuration to promote migrations from the development environment to the production environment:
data "cloud_databases" "dev" {
repo = "my-app"
env = "dev"
}
env "prod" {
url = var.url
migration {
dir = "atlas://my-app"
# Promote the migration version from the `dev` environment.
to_version = data.cloud_databases.dev.targets[0].current_version
}
}
Support for Hashicorp Vault
Database credentials are considered sensitive information and it is advised that they be stored in secure locations, so we have offered support for accessing secret stores to ensure that access to these databases remains secure. We have now added support for Atlas Pro users to access database credentials stored as secrets in Hashicorp Vault KV Secrets Engine to use in their URL configurations.
data "runtimevar" "vault" {
url = "hashivault://secret/data/database"
}
locals {
vault = jsondecode(data.runtimevar.vault)
}
env "dev" {
url = "mysql://${local.vault.username}:${local.vault.password}@aws-rds-instance.us-east-1.rds.amazonaws.com:3306/database"
dev = "docker://mysql/8/dev"
}
Discover Database Instances with Atlas Agent
Currently, Atlas Agent Discovery works only on RDS instances in AWS.
Schema monitoring with Atlas makes it easy to detect schema drifts between environments and increase the overall visibility of your schemas. Using the Atlas Agent for schema monitoring, users can now automatically discover database instances in your environment to monitor with just the click of a button. This feature is particularly useful for environments with dynamic or frequently changing databases.
Click here to start this process with ease.
Protected Flows
A protected flow requires manual approval when running a down migration. Protected flows now can be enabled on all newly created projects by default in the Atlas Cloud general settings.
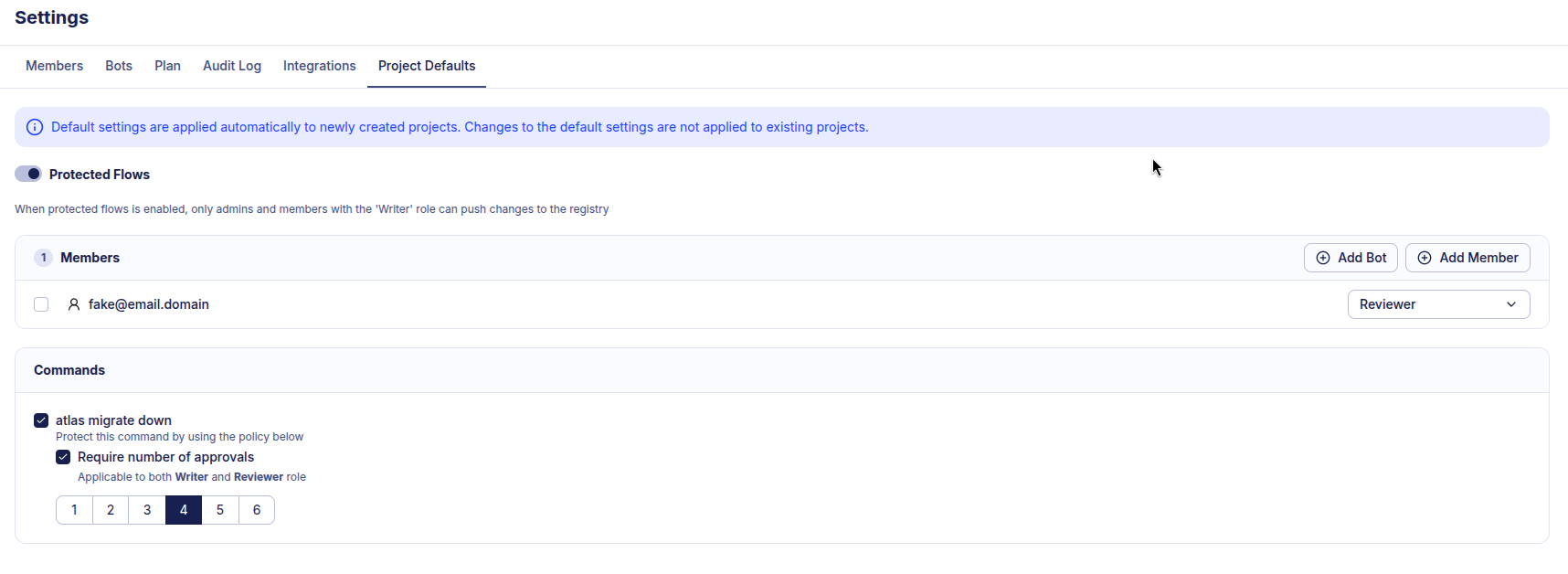
Migration approval policy enabled by default for newly created projects
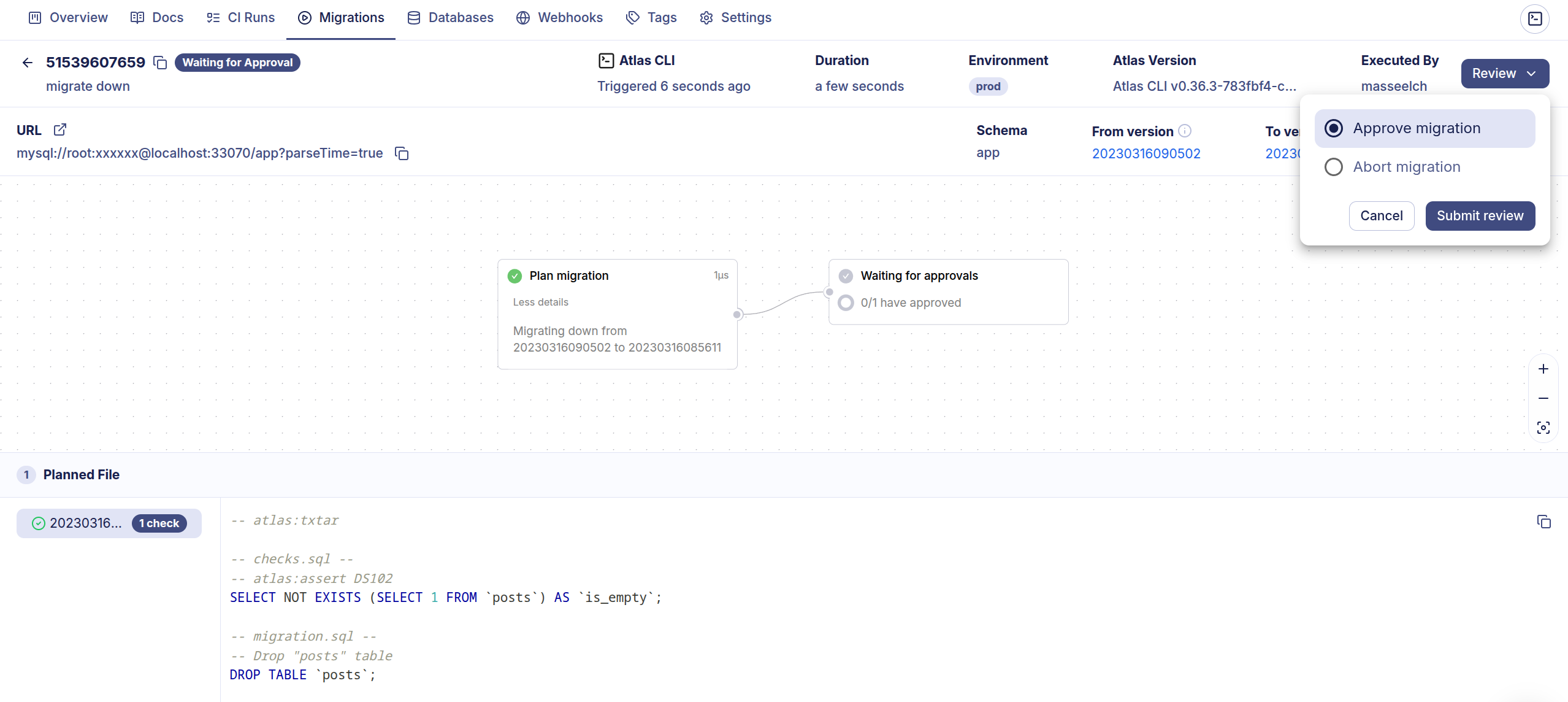
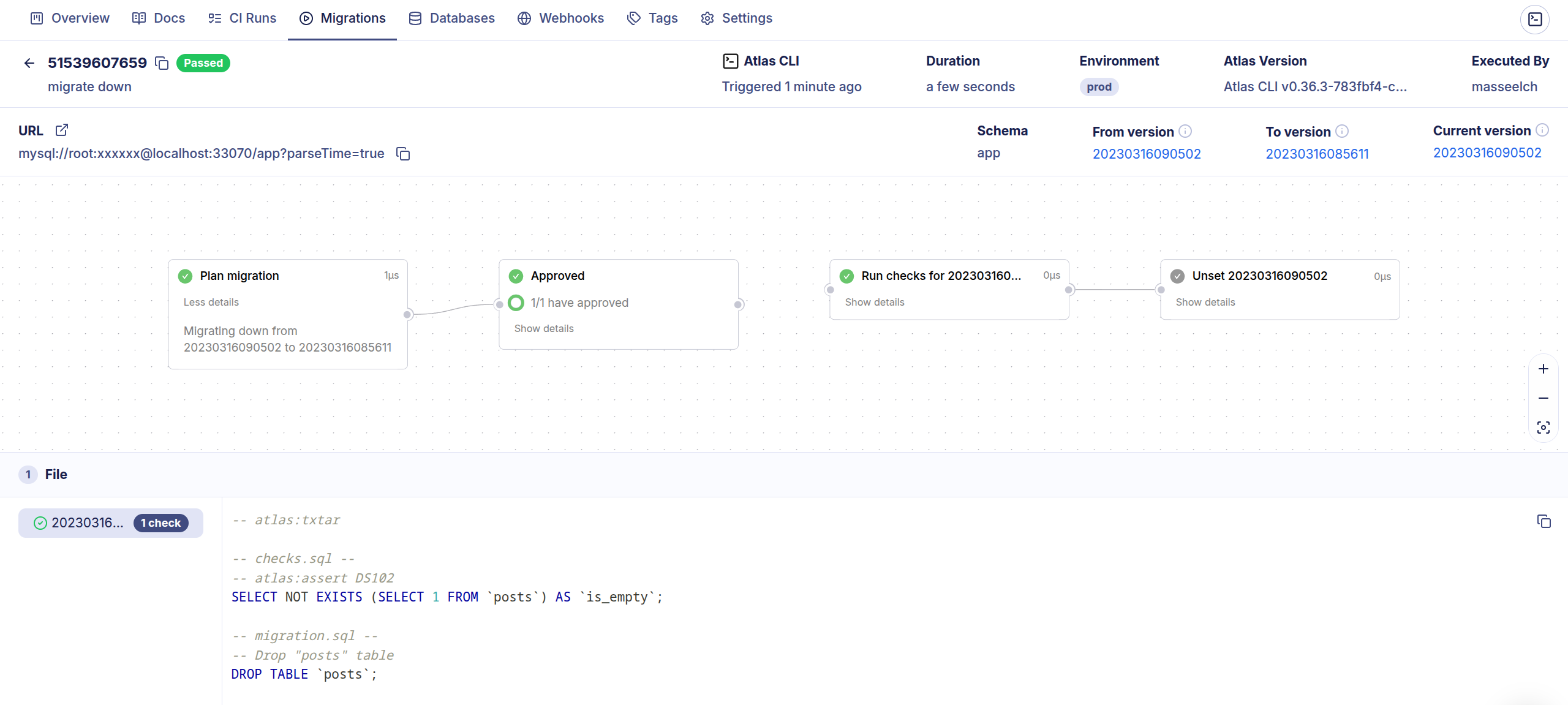
Once set, running atlas migrate down will create a plan that requires approval before being applied:
$ atlas migrate down --env prod
To approve the plan visit: https://a8m.atlasgo.cloud/deployments/51539607645
- Require Approval
- Approved and Applied
Upcoming Change in v0.38: atlas migrate lint
Starting with v0.38, the atlas migrate lint command will no longer be included in the Starter (free) plan of Atlas.
The code remains open-source (Apache 2 license) and available in Atlas Community Edition. If you need the command without
using Atlas Pro, you can still build Atlas from source or use the community binary.
We want to be transparent about this change. Over time, migrate lint was split between the Starter and Pro plans,
creating extra maintenance overhead. At the same time, the shift toward AI-driven schema changes highlights the need for
stronger, deterministic guardrails. To focus on that, we're keeping the existing lint engine in the Community build while
rewriting the new engine with advanced checks and governance features, included in the official binary and available only
in Atlas Pro.
This reduces complexity in the official binary and lets us focus on advancing Atlas in the areas teams and AI systems rely on most. Users of the free version can still run linting through Atlas Community, while Pro users remain unaffected.
Wrapping Up
Atlas v0.37 brings a lot to the table. Between the addition of Databricks support in beta and the expansions of both our ClickHouse and SQL Server support, we are making Atlas schema management accessible to more teams with unique configurations.
Additionally, with more variation around destructive changes with our linting analyzers, custom migration rules, and pre-execution checks, users have more variety with Atlas to fit their specific needs.
Database discovery for schema monitoring, protected flows by default, and the cloud_databases data source, are also giving
Atlas Cloud users more functionality with less manual configuration.
We hope you enjoy these new features and improvements. As always, we would love to hear your feedback and suggestions on our Discord server.