Strategies for Reliable Schema Migrations

Adapted from a talk given at Kube Native 2024:
Introduction
Database schema migrations are a critical part of the software development lifecycle. They allow us to evolve our data model as our application grows and changes. However, migrations can also be a significant source of risk and downtime if not handled carefully.
Despite teams applying all the common best practices, such as using a migration tool to automate changes and carefully examining each migration before approving it during code review, issues still slip through the cracks, making migrations a source of significant headaches for many engineering teams.
This post explores five strategies for making database schema migrations more reliable by introducing Atlas, a database schema-as-code tool that helps teams make their database schema changes both safer and easier to manage.
Prerequisite: Automate
Having interviewed over a hundred engineering teams about their database migration practices, we found that a surprisingly large number of teams perform database migrations manually. This involves running SQL statements via scripts or a point-and-click interface directly against the database, often without proper testing or version control.
Manual migrations are error-prone and difficult to reproduce, leading to inconsistencies between environments and increased risk of downtime. Additionally, manual changes to the database are amongst the most stressful and dreaded tasks for developers, as they can lead to nasty outages if not done correctly.
Much has been written about the importance of automating database migrations, but it's worth reiterating here. Even if you do nothing else, please automate your schema changes!
Strategy 1: Schema-as-Code
Classic database migration tools like Flyway or Liquibase are great for automating the process of executing SQL scripts against a database. However, despite being categorized as "automation tools," they still require plenty of manual work to write, test and review the SQL scripts that define the schema changes.
Atlas takes a different approach by treating the database schema as code. Instead of manually defining the schema changes in SQL scripts, developers define the desired state of the database schema in a declarative format using code and let the tool handle the rest.
For instance, a developer may define the following schema in Atlas:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
Next, to apply this schema to a database, the developer runs the following command:
atlas schema apply --env local --to file://schema.sql
Atlas will connect to the database, inspect its current schema, calculate the diff between the current and desired state, and propose a migration plan to bring the database to the desired state. The developer can then review and approve the migration before applying it.
By automating the process of defining and applying schema changes, Atlas makes it easier to manage database migrations and reduces the risk of human error.
Strategy 2: Test DB logic like any other code
Modern databases are a lot more than just containers for data. They also embody complex business logic in the form of constraints, triggers, stored procedures, and functions.
To make sure that these database objects work as expected, and keep doing so after changes are made, it's important to test them like any other code.
Atlas provides a testing framework that allows developers to write tests with a simple syntax. For example, to test a
function that returns true if the input is positive and false otherwise, a developer might write the following test:
test "schema" "positive_func" {
parallel = true
assert {
sql = "SELECT positive(1)"
}
log {
message = "First assertion passed"
}
assert {
sql = <<SQL
SELECT NOT positive(0);
SELECT NOT positive(-1);
SQL
}
log {
message = "Second assertion passed"
}
}
By treating database objects as code and writing tests for them, developers can catch make sure that their database code works reliably and consistently and prevent regressions when making changes.
Strategy 3: Test data migrations
Most commonly, migrations deal with schema changes, such as adding or removing columns, creating tables, or altering constraints. However, as your application evolves, you may need to add or refactor data within the database, which is where data migrations come in. For instance, you may need to seed data in a table, backfill data for existing records in new columns, or somehow transform existing data to accommodate changes in your application.
Data migrations can be especially tricky to get right, and mistakes can be problematic and irreversible. For this reason testing data migrations is crucial. Testing data migrations typically involves the following steps:
- Setting up an empty database.
- Applying migrations up to the one before the test.
- Seeding test data.
- Running the migration under test.
- Making assertions to verify the results.
This process can be cumbersome to set up and buggy as it often involves writing an ad-hoc program to automate the steps mentioned above or manually testing the migration.
Atlas's migrate test command simplifies this by allowing you to define test cases in a concise
syntax and acts as a harness to run these tests during local development and in CI.
Using Atlas, developers can write tests for data migrations in a simple format, making it easier to catch issues early and ensure that data migrations work as expected. For example, to test a data migration that backfills a new column with values from an existing column, a developer might write the following test:
test "migrate" "check_latest_post" {
migrate {
to = "20240807192632"
}
exec {
sql = <<-SQL
INSERT INTO users (id, email) VALUES (1, 'user1@example.com'), (2, 'user2@example.com');
INSERT INTO posts (id, title, created_at, user_id) VALUES (1, 'My First Post', '2024-01-23 00:51:54', 1), (2, 'Another Interesting Post', '2024-02-24 02:14:09', 2);
SQL
}
migrate {
to = "20240807192934"
}
exec {
sql = "select * from users"
format = table
output = <<TAB
id | email | latest_post_ts
----+-------------------+---------------------
1 | user1@example.com | 2024-01-23 00:51:54
2 | user2@example.com | 2024-02-24 02:14:09
TAB
}
log {
message = "Data migrated successfully"
}
}
In this test, the developer migrates the database to a specific version, seeds test data, runs the migration under test, and verifies the results. By automating this process, Atlas makes it easier to test data migrations and catch issues early.
Strategy 4: Automate Safety Checks
Even with the best intentions, mistakes can still happen during the development and review of migrations leading to downtime and data loss. To mitigate this risk, it's important to automate safety checks that catch common mistakes before applying the migration to the database.
Before we dive into strategies for reliable migrations, let's take a look at some common ways migrations can go wrong.
Destructive Changes
mysql> select * from dropped;
ERROR 1146 (42S02): Table 'default.dropped' doesn't exist
Migrations often involve DROP DDL statements that can lead to data loss if executed
against a table or column that still contains valuable data. Unfortunately, modern databases do not have a built-in
undo button, so once a destructive change is applied, it can be challenging (if not impossible) to recover the lost data.
This might sound like an obvious mistake to avoid, but it's surprisingly common in practice. For example, consider this published incident report from Resend, which states:
On February 21st, 2024, Resend experienced an outage that affected all users due to a database migration that went wrong. This prevented users from using the API (including sending emails) and accessing the dashboard from 05:01 to 17:05 UTC (about 12 hours).
The database migration accidentally deleted data from production servers. We immediately began the restoration process from a backup, which completed 6 hours later.
Constraint Violations
mysql> alter table candy ADD UNIQUE (name);
ERROR 1062 (23000): Duplicate entry 'm&m' for key 'candy.name'
Migrations that involve adding or modifying constraints can fail if the existing data does not meet the new constraints.
For example, adding a NOT NULL constraint to a column that already contains NULL values will cause the migration
to fail.
What makes this even more confusing is that such migrations will often succeed in a development or testing environment where the data is different from production. This can lead to a false sense of confidence that the migration is safe to apply in production.
Breaking Changes
mysql> select id, renamed_column from candy limit 1;
ERROR 1054 (42S22): Unknown column 'renamed_column' in 'field list'
A popular topic amongst data teams today is "data contracts" - the (sometimes implicit) agreement between the applications and their downstream consumers about the structure and semantics of the data. This is often mentioned in the context of data engineering teams building data pipelines, but the same concerns apply to the interface between your application backend and the database.
When a migration changes the structure of the database, it can break the contract between the application and the database, leading to runtime errors and potentially to data corruption. For example, renaming a column that is used by the application will cause queries to fail, leading to downtime and unhappy users.
Table locks
mysql> INSERT INTO candy (name, kind) VALUES ('kif-kef', 'chocolate');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Migrations that involve large tables or complex operations can cause table locks that prevent other queries from executing. This can lead to timeouts, deadlocks, and other performance issues that affect the availability of the application.
For instance, suppose your MySQL table has an enum column with a million rows, and you want to add a new value to the
enum. If you add the new value, not at the end of the enum, but in the middle (for example from ('a', 'b', 'c') to
('a', 'b', 'd', 'c')), MySQL will lock the table for the duration of the migration, while it is rewriting the column
on disk.
Preventing Risky Migrations
To prevent these common mistakes, Atlas provides a set of safety checks that run automatically before applying a migration. These checks analyze the migration and the database schema to identify potential issues and warn the developer before applying the migration.
Such checks can be run either locally during development or in CI before approving the migration and merging it into the main branch. By catching issues early, these safety checks help prevent downtime and data loss caused by risky migrations.
For instance, Atlas might warn the developer about a potentially destructive change like dropping a table:
atlas migrate lint --env local --latest 1
Might produce the following output:
Analyzing changes from version 20240929125035 to 20240929125127 (1 migration in total):
-- analyzing version 20240929125127
-- destructive changes detected:
-- L2: Dropping non-virtual column "email"
https://atlasgo.io/lint/analyzers#DS103
-- suggested fix:
-> Add a pre-migration check to ensure column "email" is NULL before dropping it
-- ok (225.916µs)
-------------------------
-- 98.996916ms
-- 1 version with warnings
-- 1 schema change
-- 1 diagnostic
Being able to identify and fix these issues while working locally can save a lot of time and headaches down the road, but this is further amplified when running these checks in CI, where teams can ensure that no risky migrations are merged into the main branch.
Strategy 5: Pre-migration checks
As we mentioned above, safety checks can catch common mistakes before applying a migration, but they are not foolproof. Some changes depend on the state of the data in the database, which cannot be determined statically by analyzing the migration script.
For example, consider a migration that adds a NOT NULL constraint to a column that already contains NULL values.
A safety check can warn the developer about this potential issue, but it cannot guarantee that the migration will succeed
in all cases. Similarly, a migration that drops a column might be safe and reversible if the column is empty, but risky
if it contains valuable data.
To handle these cases, Atlas provides a mechanism for defining pre-migration checks that run before applying the migration. These checks can analyze the state of the database and the data to determine if the migration is safe to apply. In case of an issue, the check can prevent the migration from running and provide guidance on how to resolve the issue.
For instance, the code below defines a pre-migration check that ensures the table users is empty before dropping it:
-- atlas:txtar
-- checks.sql --
-- The assertion below must be evaluated to true. Hence, table users must be empty.
SELECT NOT EXISTS(SELECT * FROM users);
-- migration.sql --
-- The statement below will be executed only if the assertion above is evaluated to true.
DROP TABLE users;
Summary
Database schema migrations are a critical part of the software development lifecycle, but they can also be a significant source of risk and downtime if not handled carefully. By following the strategies outlined in this post and using tools like Atlas, teams can make their database schema migrations more reliable and reduce the risk of downtime and data loss.
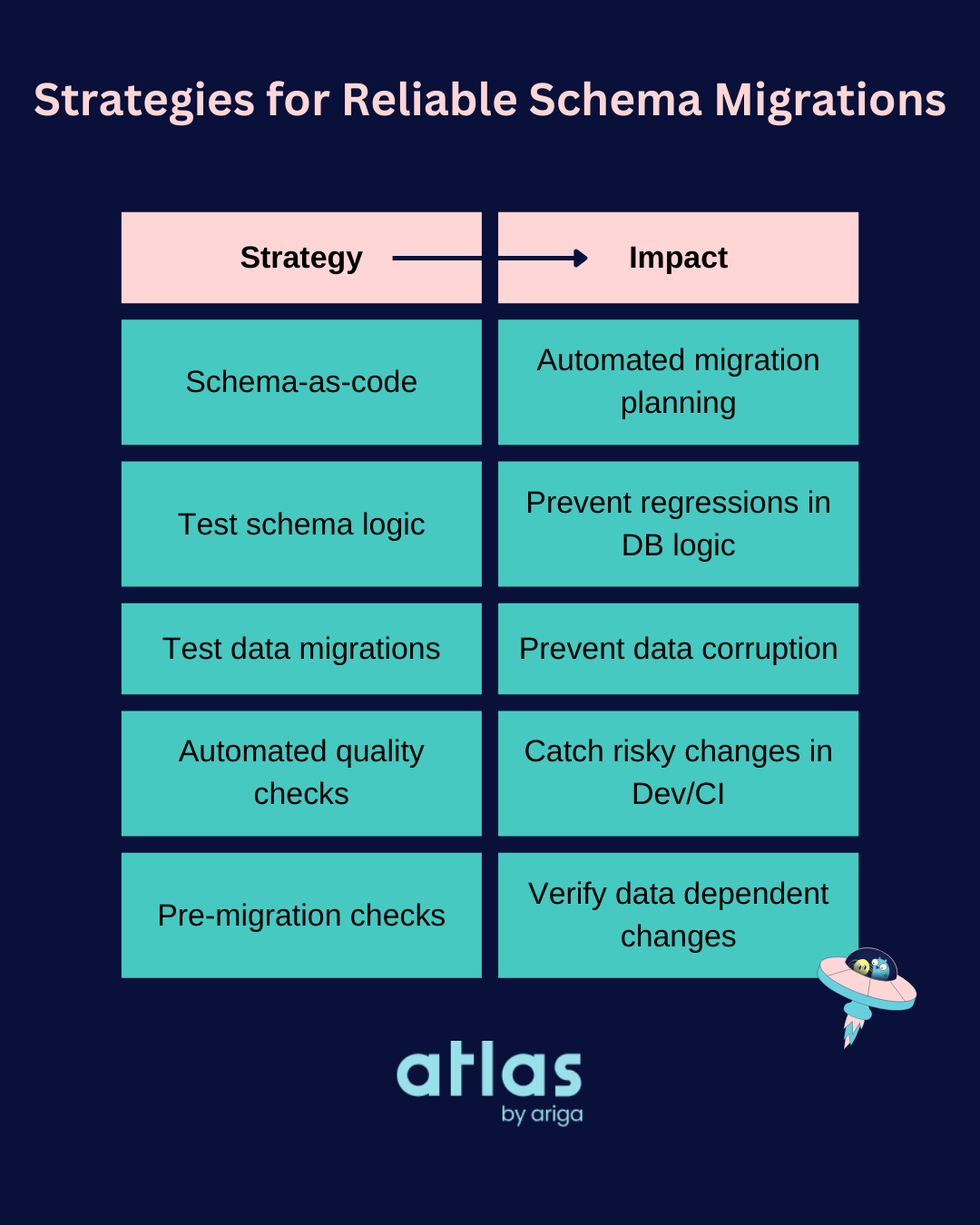
To summarize, here are the five strategies for reliable schema migrations:
| Strategy | Impact |
|---|---|
| Schema-as-code | Automated migration planning |
| Test schema logic | Prevent regressions in DB logic |
| Test data migrations | Prevent data corruption |
| Automated quality checks | Catch risky changes in Dev/CI |
| Pre-migration checks | Verify data dependent changes |
We hope you enjoyed this post and found it useful. As always, we welcome your feedback and suggestions on our Discord server.