Snowflake Schema Management: Atlas vs schemachange vs SnowDDL

Snowflake's cloud data platform has transformed data warehousing, yet many teams still manage schema changes using manually-composed SQL scripts and verification processes. As data teams grow and pipelines become more complex, these approaches often become more challenging to maintain and much riskier to use.
Schema changes in production environments can quickly lead to unexpected behavior and inconsistent data, and having more contributors increases the risk of human error leading to costly downtime or data integrity issues. These cases are familiar to many data teams because the traditional manual database deployment methods come with implicit risks.
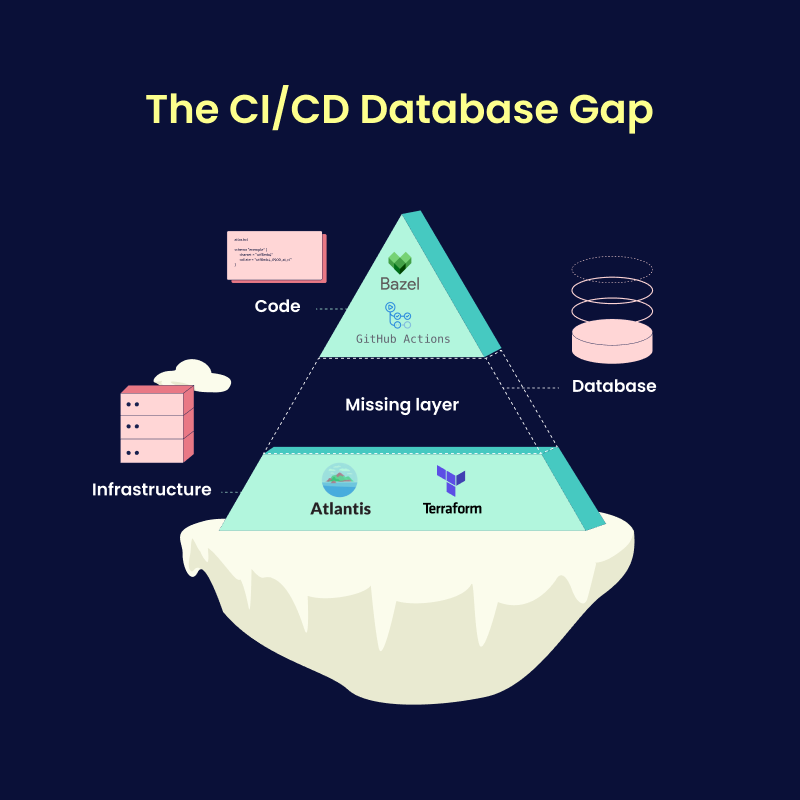
To address these challenges, Snowflake teams have begun adopting tools to automate schema changes, enforce safety checks, and ensure consistent deployments across environments.
In this post, we will compare three popular Snowflake schema management tools – Atlas, schemachange, and SnowDDL – and guide you in building reliable CI/CD pipelines to deploy schema changes with more confidence and control.