The Missing Chapter in the Platform Engineering Playbook

Prepared for SREDay London 2025
Introduction
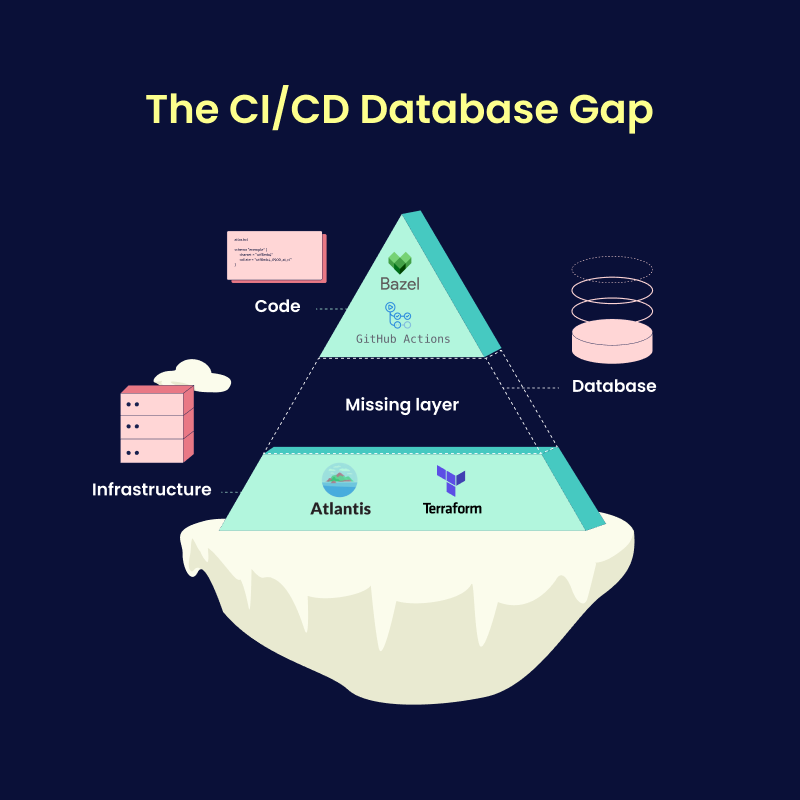
Platform engineering is rapidly emerging as a discipline aimed at reducing cognitive load for developers, enabling self-service infrastructure, and establishing best practices for building and operating software at scale. While much of the conversation focuses on CI/CD, Kubernetes, and internal developer platforms, one crucial aspect often remains overlooked: database schema management.
Despite being at the heart of nearly every application, schema changes are still a major source of friction, outages, and bottlenecks. In this post, we'll explore why database schema management deserves a dedicated chapter in the platform engineering playbook and how organizations can integrate it into their platform strategies.
The prompt that nuked the database
Let me tell you a not-so-fictional story about a developer named Alice. Alice is a backend engineer at a fast-growing
startup. One day, her manager asked her to make a small change to the database. The data engineering team was
complaining that they were seeing duplicate emails in the user table, and they suspected that the email column did
not have a unique constraint.