Atlas vs Alembic: Why Modern Teams Choose Atlas
Modern database development requires deterministic planning, end-to-end automation, and guardrails that prevent outages. Atlas is a schema-as-code system that supports both declarative and versioned workflows, integrates deeply with CI/CD, and offers integrated policy and testing frameworks. Alembic is the migration tool for SQLAlchemy: it runs ordered Python revision scripts and can autogenerate them by comparing your SQLAlchemy models to the database.
This document summarizes Atlas's capabilities and compares them with Alembic's to help you decide which tool is best for your team.
This document is maintained by the Atlas team and was last updated in June 2026. It may contain outdated information or mistakes. For Alembic's latest details and their own documentation, please refer to the official Alembic and SQLAlchemy websites.
Quick Comparison
| Feature / Capability | Atlas | Alembic |
|---|---|---|
| Language / Ecosystem | Language-independent. Works with any stack and reads desired state from HCL, SQL, or ORMs (SQLAlchemy, Django, GORM, Hibernate, Drizzle, and more) | Python only, tightly coupled to SQLAlchemy |
| Workflows | Declarative (state-based) and versioned | Versioned only (ordered Python revision scripts) |
| Migration Planning | Automatic diff-based planning with policy-awareness and checks | autogenerate diffs SQLAlchemy models against the database, but the output is incomplete and must be reviewed and edited by hand |
| Rollback / Down Migrations | Dynamic, state-aware rollback with safety checks | Manual downgrade() function per revision. Assumes the upgrade() succeeded fully; partial failures are not handled |
| Migration Safety Checks | Built-in safety analysis flags destructive changes, table locks, data loss, and schema drift, plus policy checks and CI/CD enforcement | Not available |
| Testing Framework | Unit-style schema/data-migration tests. Tests can run locally and in CI/CD, with auto-generation supported | Not available (teams roll their own with pytest) |
| Policy Enforcement | Policies are enforced at every step: planning changes (diff), generating the migration (plan), reviewing for unsafe changes (lint), and deploying to the database (apply) | Not available |
| CI/CD Integration | Native GitHub, GitLab, Azure DevOps, Bitbucket, CircleCI actions | Requires custom scripting |
| Kubernetes Integration | Official Kubernetes Operator with CRDs (AtlasSchema, AtlasMigration), GitOps-ready, Argo CD supported | No official operator |
| Terraform Integration | Official Terraform Provider (atlas_schema, atlas_migration) | No official provider |
| Multi-tenant Migrations | Built-in support for DB-per-tenant and schema-per-tenant | Ships a rudimentary built-in multidb template; DB-per-tenant/schema-per-tenant at scale is DIY |
| Secrets Manager Integration | Supports environment variables and standard secret managers (AWS, GCP, Azure, etc.) in community edition (Vault support in Pro) | Manual, via your own Python configuration |
| Database Support | PostgreSQL, MySQL/MariaDB, SQL Server, Oracle, ClickHouse, SQLite, CockroachDB, TiDB, Redshift, Spanner, Snowflake, and more | Any database with a SQLAlchemy dialect, but autogenerate detection quality varies by dialect |
| AI Integration | Atlas Copilot built-in assistant for schema guidance and testing, plus integration with Copilot, Cursor, and Claude Code (all executed through Atlas's deterministic engine) | Not available |
| Database Security as Code | Declarative roles, users, grants, and permissions with automatic diffing | Not supported - requires manual op.execute() of GRANT/REVOKE in revisions |
| Declarative Data Management | Define seed data in desired state; Atlas computes minimal diffs | Manual bulk_insert() / data migrations; no upsert, no declarative diffing |
Migration Workflows: Declarative and Versioned
Atlas supports two workflows for managing schema changes: declarative (state-based) and versioned (migrations-based). In both workflows, Atlas inspects the "current state," compares it to the "desired state," and plans the necessary statements to reach the desired state using a single deterministic migration planner.
Current State vs Desired State
- Current state: In the declarative workflow (Terraform-like workflow), the current state is typically a live database. In the versioned workflow, the current state is the result of applying all migration files in order. Atlas supports both workflows.
- Desired state: The desired state defines the target schema. It can be defined using HCL schema files, SQL schema files, another database, ORM providers (such as SQLAlchemy, Django, Hibernate, GORM, or Drizzle), or a combination of these sources. For example, you can define your core schema in SQLAlchemy and augment it with SQL files that add triggers, RLS policies, functions, or other constructs.
Key Differences Between Atlas and Alembic
Alembic is a versioned-only tool. You either write the upgrade() and downgrade() functions in each revision by hand, or
use autogenerate to draft them by comparing your SQLAlchemy models to the database - a starting point that you then review
and refine before applying.
Atlas takes a different approach:
- Declarative - Atlas compares the desired state to the current database and plans the changes based on your policies,
then applies them to the target database. This mirrors Terraform:
schema planpreviews a migration liketerraform plan, andschema applyexecutes it liketerraform apply. - Versioned - You define the desired schema in code (or another database), and run
atlas migrate diffto generate migration files that transition the current state of the migrations directory to the desired state with rename detection, policy-awareness, and linting built in.
Both workflows can be automated in CI/CD using Atlas Actions (GitHub, GitLab, Azure DevOps, etc.) or the Atlas CLI. After changes are planned, Atlas validates them with migration linting and policy checks before execution. From there, changes can be streamlined through environments (dev, staging, production) with a controlled promotion process using the Atlas Kubernetes Operator, the Atlas Terraform Provider, and other deployment integrations.
Using Atlas with SQLAlchemy
Since Alembic is tied to SQLAlchemy, the most common question from Python teams is whether they can keep their SQLAlchemy models and replace Alembic. They can. Atlas ships a SQLAlchemy provider that loads your existing models as the desired state, so you continue defining tables in Python while Atlas plans the migrations.
You point an atlas.hcl configuration at your models, and Atlas plans the migrations with no upgrade() / downgrade()
to write by hand:
pip install atlas-provider-sqlalchemy
data "external_schema" "sqlalchemy" {
program = [
"atlas-provider-sqlalchemy",
"--path", "./models", // path to your SQLAlchemy models
"--dialect", "postgresql"
]
}
env "sqlalchemy" {
src = data.external_schema.sqlalchemy.url
dev = "docker://postgres/16/dev?search_path=public"
migration {
dir = "file://migrations"
}
}
atlas migrate diff --env sqlalchemy
From there you get the rest of Atlas: safety checks, policy enforcement, a declarative apply option, and testing. You can also compose SQL alongside your models to manage objects SQLAlchemy can't express, such as triggers, functions, and extensions. For an example, see Row-Level Security with SQLAlchemy.
One standard across every team
Atlas also becomes a single, consistent tool across your whole organization. Each team can define its desired state in whatever fits best (e.g., one team uses SQLAlchemy, another Drizzle, GORM, or plain SQL) so only the diff and plan stages differ per team. Everything downstream is identical: the same CI checks, CD and deployment flow, drift detection, and policy enforcement apply across every team, no matter how each one defines its schema.
See the full example in the SQLAlchemy getting-started guide.
Migration Safety, Policy, and Governance
Atlas pioneered a code-first methodology for database management. Database logic is treated like application code: it can be linted, validated, and unit-tested after each change. By bringing modern software engineering practices such as static analysis, validation, and automated testing into schema management, Atlas provides a level of safety and reliability not found in script-based migration tools like Alembic:
- Testing framework - Atlas's testing framework lets you write unit-style tests for schema and data migrations. Tests run locally and in CI to catch issues before deployment. With Atlas Skills, AI agents like Claude or Codex can generate these tests for you.
- Policy-aware planning - Changes are checked against team policies (e.g., create indexes concurrently). Planning is not just about moving from state A to state B, but doing so in a way that respects your team's conventions and requirements.
- Validation and analyzers - The
atlas migrate lintandatlas schema lintcommands check migrations for semantic correctness, warn about locking operations, table copies, destructive changes, and incompatible modifications to suggest safer alternatives. Linters run locally and in CI/CD. They respect company policies and work on both migration files and schema definitions. Atlas Actions in CI can block merges if linting fails and support code comments in SQL, HCL, Go, Python, Java, and more. - Policy enforcement - Using the Atlas Rules Language, you can express virtually any rule (naming conventions, banning foreign keys, and more), enforced automatically during diff, lint, and apply.
- Pre-migration checks - Embed SQL assertions in a migration to verify conditions (e.g., a table is empty before dropping it). If a check fails, the migration aborts.
- Linear history - Atlas enforces a linear migration history, automatically detecting the conflicts that arise when multiple branches or pull requests introduce overlapping changes, and catching them in CI before they merge.
Alembic provides none of the above out of the box. It executes revision scripts in order and tracks the current head(s) in
an alembic_version table. Alembic does offer post-write hooks (to run external formatters or linters such as Ruff or Black
on generated files) and an alembic check command to detect when a new migration is needed, but it has no semantic
migration-safety analyzer, policy engine, or testing framework. These are left to the team and the wider ecosystem (e.g. pytest-alembic).
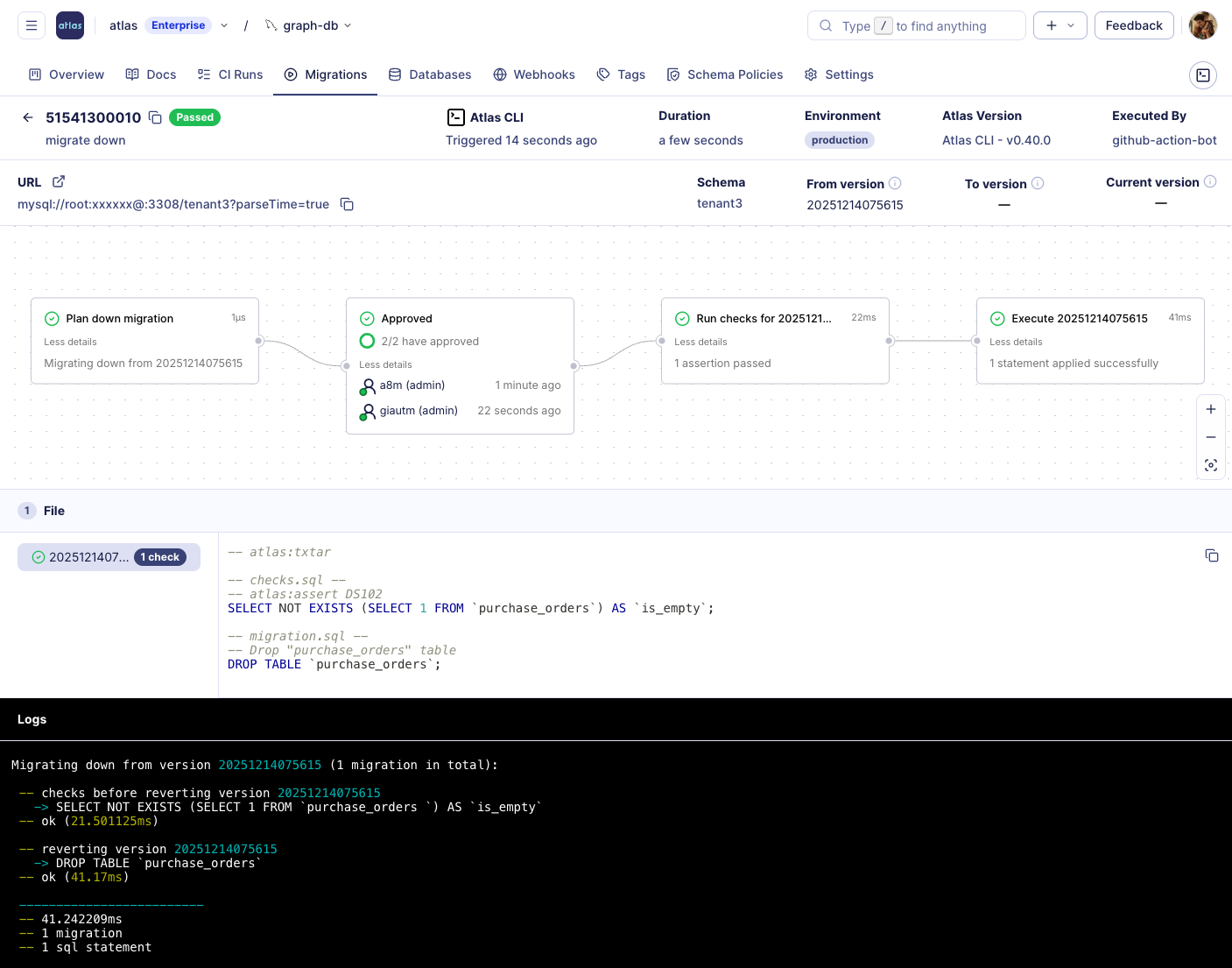
Down Migrations and Rollback
Rolling Back vs Going Down
Rolling back schema changes is often confused with "going down", but the concepts are not the same:
- Rollback - Happens at the transaction level. If a migration fails in a database that supports transactional DDLs (like PostgreSQL), the entire transaction is aborted and the schema returns to its pre-migration state. On databases without transactional DDLs (like MySQL), a failed migration may leave the schema partially applied.
- Going Down - Refers to intentionally reverting previously applied migrations to reach an earlier version or tag. This requires the migration tool to understand the database state and apply reverse changes across multiple files. The tool must generate a short, safe sequence of statements that revert the schema to the desired state, even if the last migration was partially applied or failed.
Alembic vs Atlas
- Alembic - Each revision has a
downgrade()function that you write manually (or thatautogeneratedrafts as the inverse ofupgrade()). Downgrades assume the upgrade succeeded fully and do not handle partial failures. They are easy to get wrong and, in practice, are frequently left as stubs. - Atlas - The
atlas migrate downcommand computes a rollback plan dynamically. It inspects the current database state and generates the exact sequence of statements required to revert to a chosen version, tag, or number of steps back.- Works even if the last migration was partially applied or failed.
- Runs pre-migration checks by default to prevent destructive operations.
- Supports
--dry-runfor previews, and in Atlas Cloud you can enforce review/approval policies before execution. - Executes transactionally when supported, or statement-by-statement with proper history tracking.
- Approval workflows can be enforced in CI/CD or Atlas Cloud for down migrations.
CI/CD Integration and Platform Fit
Unlike Alembic and other script-based tools, Atlas is built for modern delivery pipelines. It ships native CI/CD actions for GitHub, GitLab, CircleCI, Bitbucket, and Azure DevOps that post PR comments and can block merges when linting fails, and Atlas Cloud can send Slack and webhook alerts on drift or migration events. For deployment, it integrates with the two platforms teams rely on most:
- Kubernetes Operator
- Terraform Provider
Atlas provides a production-ready Kubernetes Operator that manages schema state as a first-class Kubernetes resource using
CRDs. You can choose between declarative or versioned workflows, backed by AtlasSchema and AtlasMigration CRDs respectively.
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasSchema
metadata:
name: myapp-schema
spec:
url: postgresql://myapp-db:5432/myapp
schema:
sql: |
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) UNIQUE NOT NULL
);
policy:
lint:
destructive:
error: true
- Declarative (desired-state) and versioned workflows, backed by
AtlasSchemaandAtlasMigrationCRDs. - Flexible installation: environments, project settings, SSL certificates, and secret management.
- Pre-approval and ad-hoc approval flows, so changes are gated or auto-approved by policy or environment.
- Automatic drift reconciliation against the declared CRD schema.
For GitOps, sync schema manifests via Argo CD or Flux using Git as the single source of truth, applying changes in sync waves (database → schema → app). Alembic doesn't provide an official Kubernetes Operator.
Atlas offers a first-class Terraform provider that makes database schemas part of your Infrastructure-as-Code workflows.
resource "atlas_schema" "myapp" {
hcl = file("schema.hcl")
url = var.database_url
dev_db_url = "docker://postgres/15/dev"
}
Use the atlas_schema resource for declarative changes or atlas_migration for versioned ones, with state management,
drift detection, and approval gates built in. Alembic has no official Terraform provider.
Atlas Cloud: Registry, Docs, and Drift Monitoring
Atlas Cloud centralizes schema management. When you push schemas and migrations to the registry, you get:
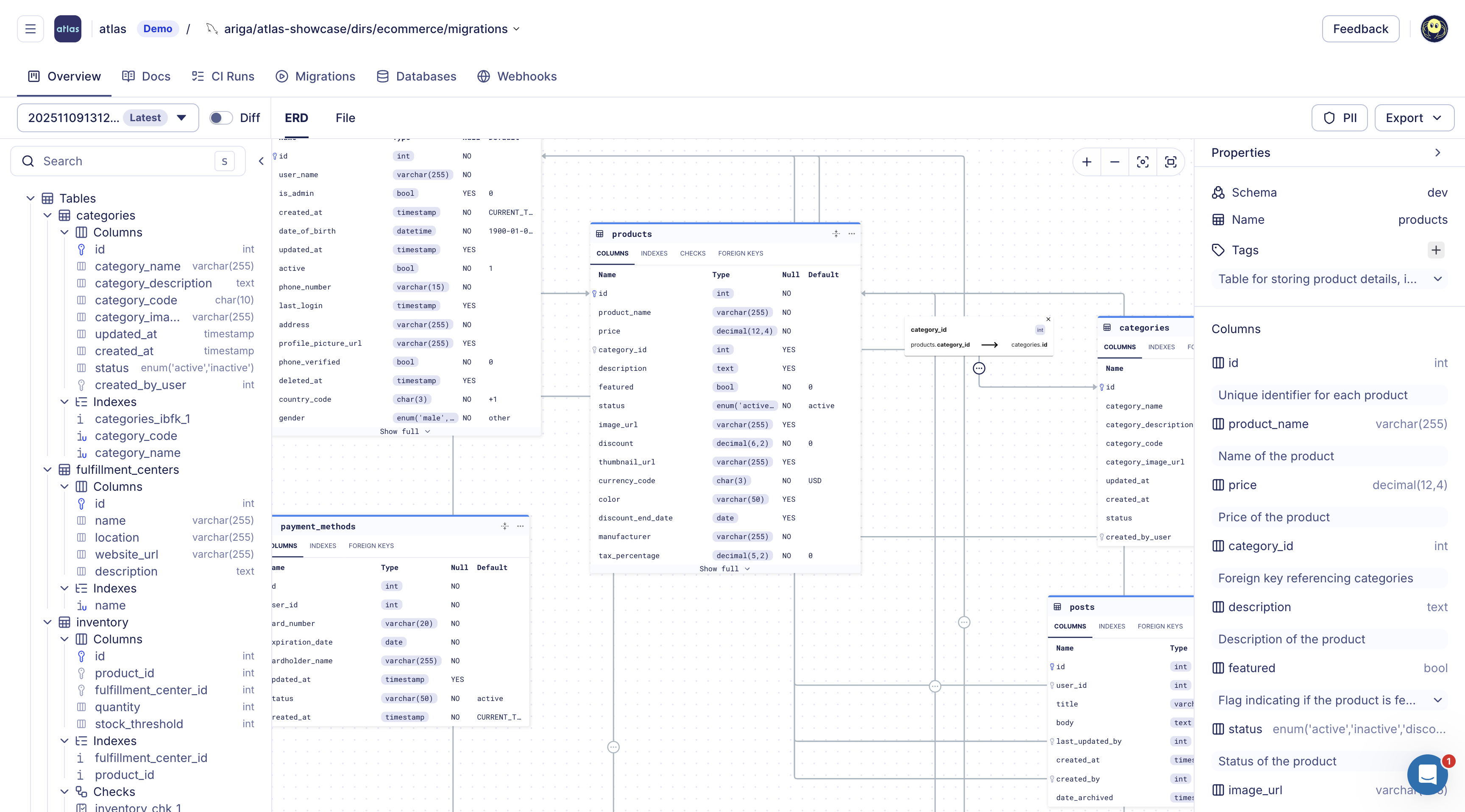
- Schema Registry - A central store for schema versions and migration directories. Each push generates an ER diagram, searchable documentation, and SOC2-audited history of schema and migration changes.
- Always-up-to-date docs - Cloud regenerates human-readable documentation and ERDs whenever a new version is pushed. Documentation is derived from schema and migration files only, ensuring accuracy and avoiding direct database or SCM connections.
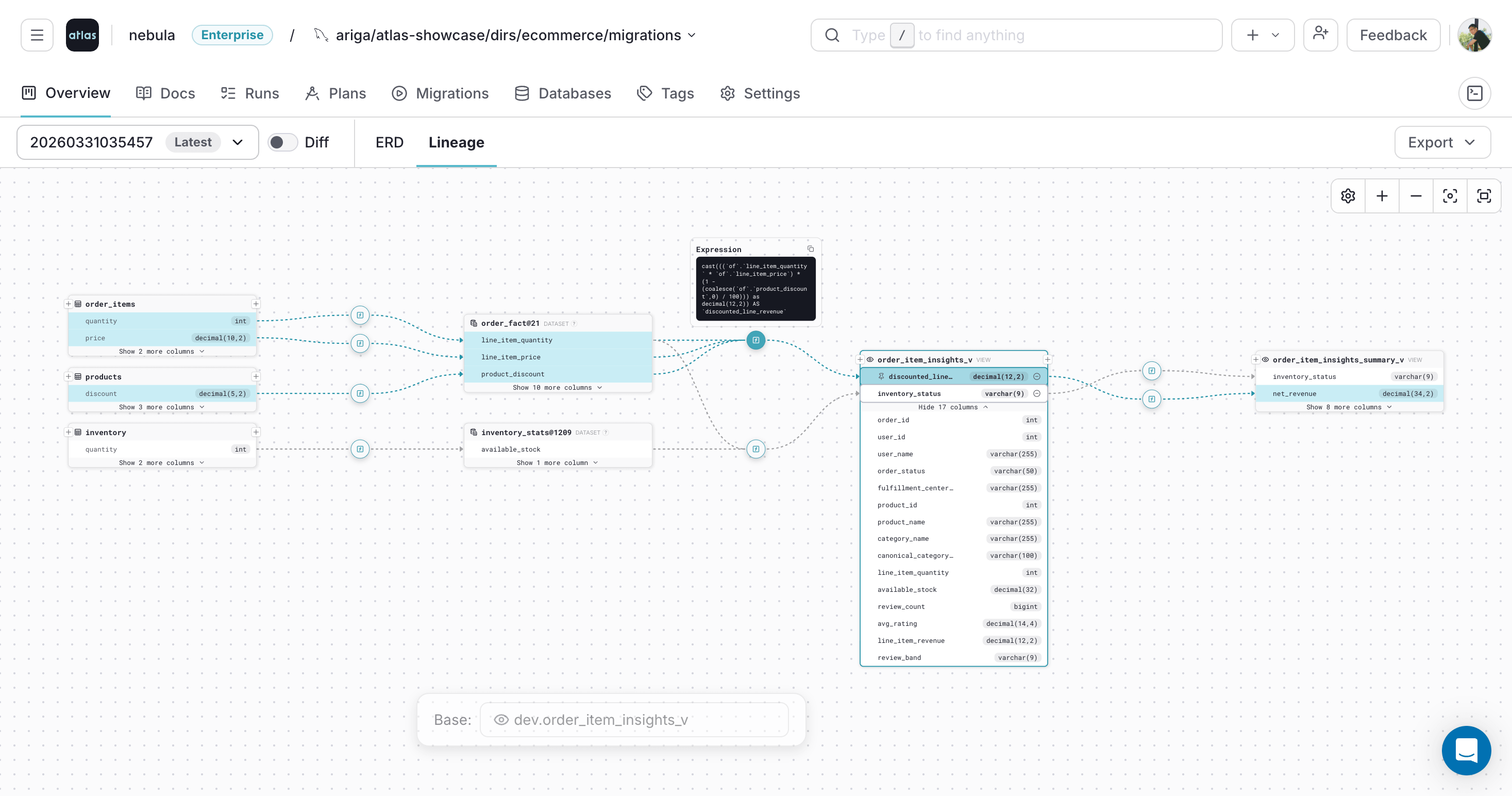
- Column-level lineage - Trace how columns are derived across tables, views, and datasets.
- Pull-request checks - Cloud allows running the same linters and policy checks in CI and can block merges if rules are violated.
- Environment promotion - Promote a tested schema version through environments (dev, staging, production) with a controlled, auditable process.
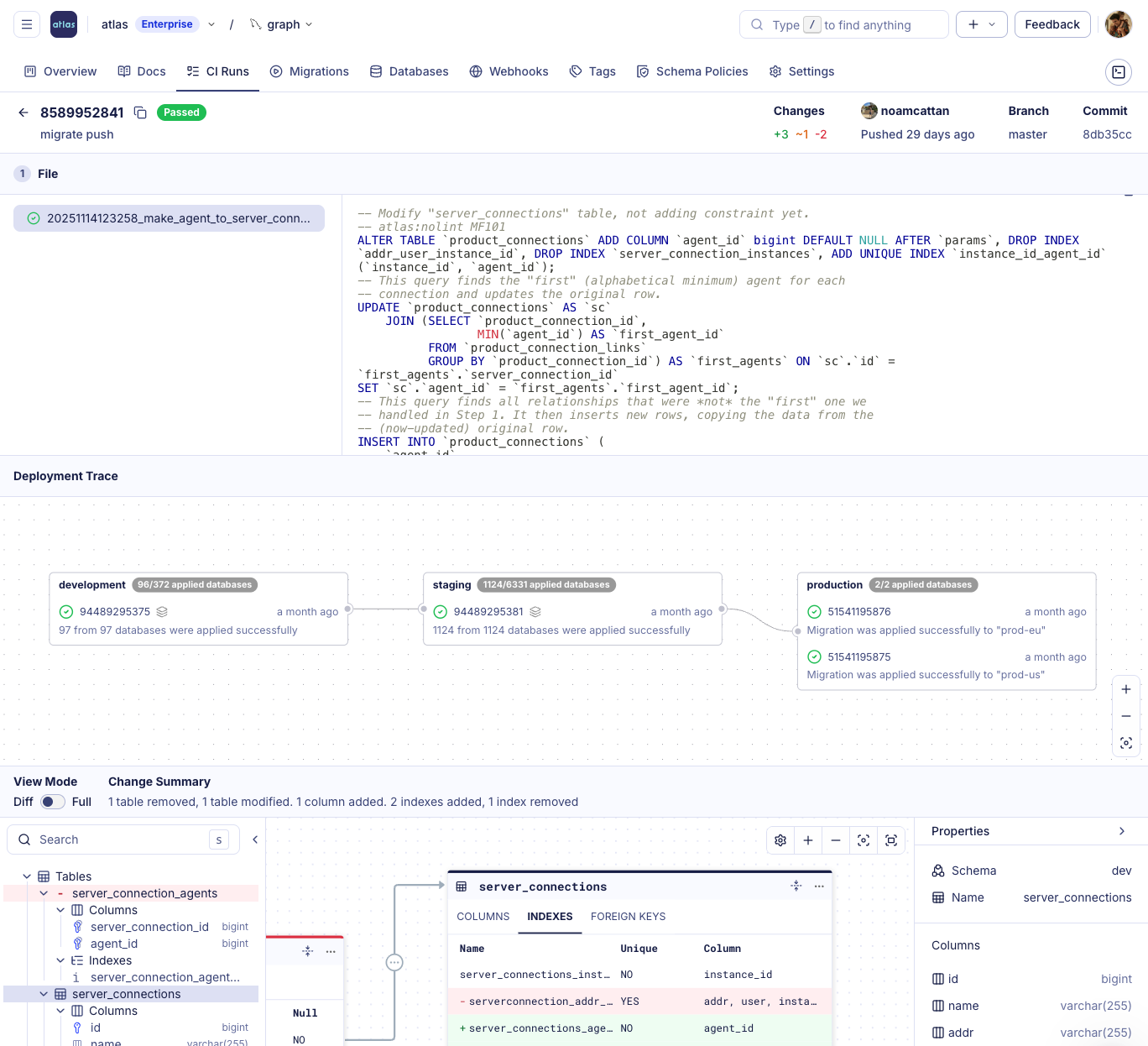
- Deployment tracking - See which version is deployed to each target database, with full deployment history and a trace for every change.
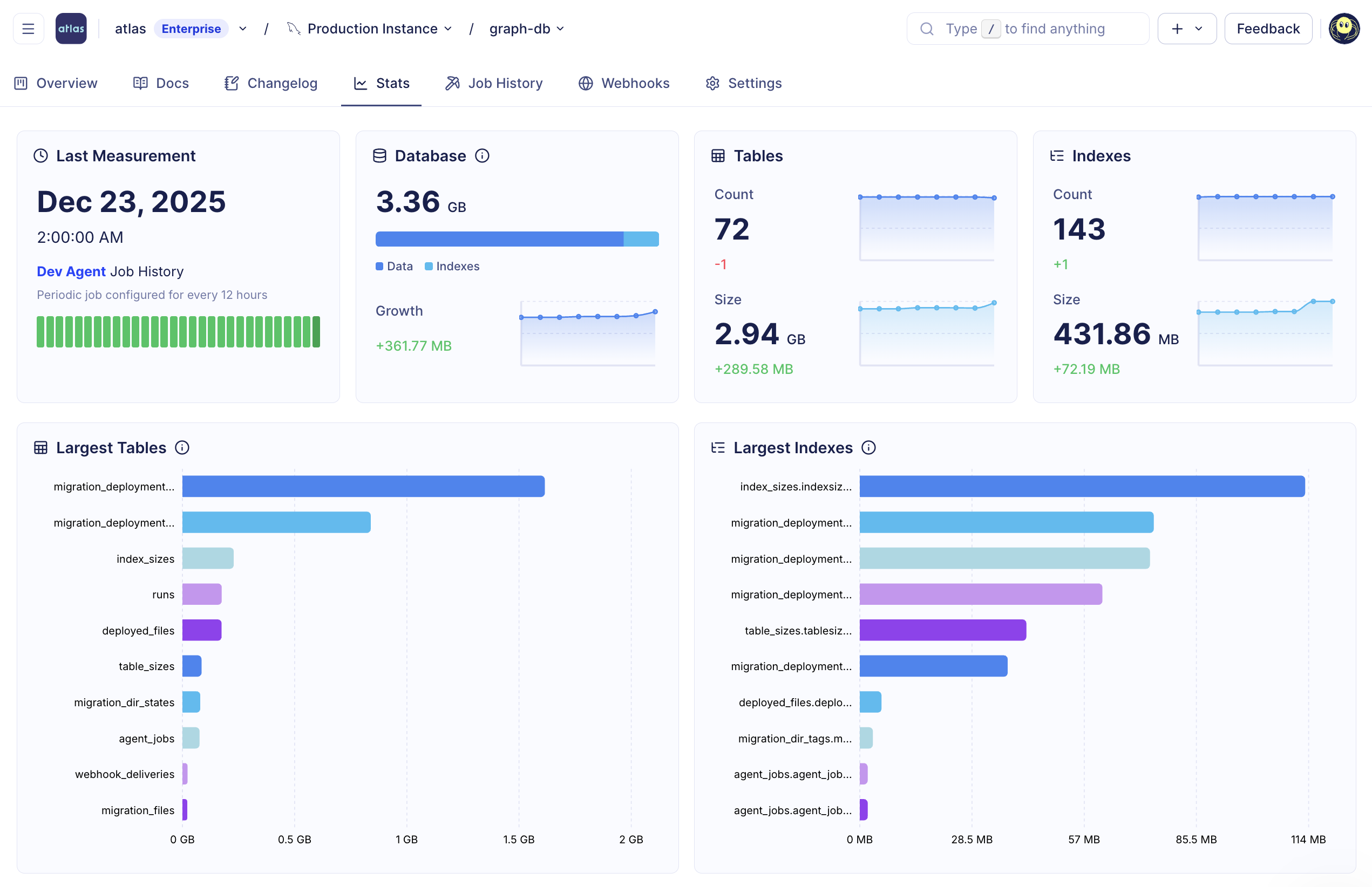
- Drift detection - Using Atlas Agent or CI actions, you can inspect production databases continuously. If the actual schema drifts from the expected state, Cloud sends alerts with detailed HCL/SQL diffs.
- Notifications - Configure Slack and webhook alerts to be notified of drift, failed migrations, or other events.
- Column-Level Lineage
- ERD
- Deployment Trace
- Schema Monitoring
- Approval Flows
Multi-tenant Migrations
Atlas includes built-in support for managing multi-tenant database environments, commonly used in database-per-tenant and schema-per-tenant architectures. With Atlas, teams can define logical tenant groups to plan and apply schema changes across many databases in a single operation. This simplifies the management of large fleets while ensuring consistency and reducing the risk of drift or deployment errors.
- Multi-Tenant
- Staged Rollout
Define your tenants once and Atlas applies changes across all of them in a single operation:
variable "db_instance_url" {
type = string
}
locals {
tenants = ["acme_corp", "widget_inc", "wayne_enterprises", "stark_industries"]
}
env "tenants" {
for_each = toset(local.tenants)
url = urlsetpath(var.db_instance_url, each.value)
}
For large fleets, stage the rollout so a change reaches canary tenants first and only continues to the rest once they pass:
deployment "staged" {
variable "name" {
type = string
}
// Canary tenants first
group "canary" {
match = startswith(var.name, "canary-")
}
// Then everyone else, only after canary succeeds
group "rest" {
parallel = 10
depends_on = [group.canary]
}
}
env "tenants" {
for_each = toset(local.tenants)
url = urlsetpath(var.db_instance_url, each.value)
rollout {
deployment = deployment.staged
vars = {
name = each.value
}
}
}
To learn more, check out the Database-per-Tenant guide and staged rollouts.
Database Security as Code
Managing database access control (roles, users, grants, and permissions) is a critical responsibility, especially in regulated industries.
Alembic does not provide built-in support for declarative management
of security objects. Teams must manually emit GRANT, REVOKE, CREATE ROLE
and similar statements via op.execute() in versioned revisions. There is no
automated diffing, drift detection, or policy enforcement for security
objects.
Atlas provides Database Security as Code. Teams define their desired security posture (roles, users, grants, and permissions) declaratively alongside their schema in HCL or SQL. Atlas diffs the current security state against the desired state and plans the required changes automatically. Security changes flow through the same CI/CD pipeline as schema changes - linted, reviewed, and deployed with full audit trails.
- HCL
- SQL
- Security Policy
role "app_reader" {
login = false
}
role "app_writer" {
login = true
member_of = [role.app_reader]
}
permission {
to = role.app_reader
for = table.users
privileges = [SELECT]
}
permission {
to = role.app_writer
for = table.users
privileges = [SELECT, INSERT, UPDATE]
}
CREATE ROLE app_reader NOLOGIN;
CREATE ROLE app_writer LOGIN IN ROLE app_reader;
GRANT SELECT ON TABLE users TO app_reader;
GRANT SELECT, INSERT, UPDATE ON TABLE users TO app_writer;
Enforce security policies with the rules engine. For example, application roles must never be SUPERUSER:
predicate "role" "is_app_role" {
name { match = "^app_.*" }
}
predicate "role" "not_superuser" {
superuser { eq = false }
}
rule "schema" "no-superuser-app-roles" {
description = "Application roles must not be SUPERUSER"
role {
match {
predicate = predicate.role.is_app_role
}
assert {
predicate = predicate.role.not_superuser
message = "role ${self.name} is SUPERUSER and will bypass RLS"
}
}
}
Beyond defining and diffing security state, Atlas lets teams enforce custom security policies using its schema rules engine.
This completes the security lifecycle: define → diff → enforce → audit. For an overview of how Atlas supports database governance end-to-end, see the Database Governance use case.
Declarative Data Management
Applications often depend on reference data (lookup tables, feature flags, configuration values) that must exist for correct operation.
Alembic supports data migrations through op.bulk_insert() and arbitrary
op.execute() statements inside a revision. However, Alembic has no upsert
logic and does not diff current data against a desired state. The developer
must write the full INSERT, UPDATE, or DELETE logic by hand, and keep the
downgrade() in sync.
Atlas provides Declarative Data Management. Teams define
seed data directly in their desired state file using HCL data blocks
or SQL INSERT statements. Atlas computes the minimal set of INSERT,
UPDATE, or DELETE statements needed to bring the data to the desired
state. Sync modes include INSERT, UPSERT, and SYNC. Data is versioned alongside
the schema and deployed through the same CI/CD pipeline.
- HCL
- SQL
- Data Configuration
table "countries" {
schema = schema.public
column "id" {
type = int
}
column "code" {
type = varchar(2)
}
column "name" {
type = varchar(100)
}
primary_key {
columns = [column.id]
}
}
data {
table = table.countries
rows = [
{ id = 1, code = "US", name = "United States" },
{ id = 2, code = "IL", name = "Israel" },
{ id = 3, code = "DE", name = "Germany" },
]
}
CREATE TABLE countries (
id INT PRIMARY KEY,
code VARCHAR(2) NOT NULL,
name VARCHAR(100) NOT NULL
);
INSERT INTO countries (id, code, name) VALUES
(1, 'US', 'United States'),
(2, 'IL', 'Israel'),
(3, 'DE', 'Germany');
Data sync is opt-in. Enable it per environment in atlas.hcl and pick a sync mode: INSERT (add new rows only), UPSERT (insert and update), or SYNC (full reconcile, including deletes):
env "dev" {
# ...
data {
mode = UPSERT
include = ["countries", "currencies"]
}
}
To learn more, see the HCL or SQL data management docs.
Why Teams Replace Alembic with Atlas
Alembic works with any database that has a SQLAlchemy dialect, but its functionality is limited to running revision scripts
and to whatever autogenerate can detect for that dialect, which varies in quality and completeness. Atlas natively
supports a wide range of databases and provides deep functionality for each: schema inspection and diffing,
automatic migration planning, policy enforcement, testing, and drift detection.
Teams adopt Atlas for deterministic planning and end-to-end safety. Rather than hand-writing upgrade() and downgrade()
functions, you define the desired schema once (in HCL, SQL, or an ORM such as SQLAlchemy) and Atlas plans the migration for
you. It detects renames and ambiguous changes instead of emitting drop-and-add like autogenerate, and computes
state-aware rollbacks that handle partial failures instead of relying on downgrade() stubs.
From there, the same workflow adds the guardrails that script runners leave to you: policy as code to enforce conventions and block unsafe changes, a testing framework with linting and assertions to catch errors before deployment, and conflict detection that keeps migration history linear across branches. Atlas Cloud centralizes documentation, ERDs, and drift alerts as a single source of truth, while built-in multi-tenant support applies changes across thousands of databases in one operation.
Because Atlas is language-independent, this works across Python, Go, Java, JS/TS, C#, and more, not just SQLAlchemy. It also fits modern delivery: AI agents like Copilot, Cursor, and Claude Code run through Atlas's deterministic engine, and the Kubernetes Operator and Terraform provider let you manage schema changes as declarative infrastructure with GitOps tools like Argo CD.
Summary
Both Atlas and Alembic serve their purpose in the ecosystem. Alembic is a solid, widely-used migration runner for SQLAlchemy projects and established important patterns for Python database migrations. Atlas takes schema management further with a modern, language-independent, cloud-native approach that supports both declarative and versioned workflows, with comprehensive safety features and infrastructure integration, and it can read your existing SQLAlchemy models so Python teams can adopt it without rewriting their schema.
To try it on your own project, follow the Getting Started with SQLAlchemy guide.