CI/CD for Databases on Bitbucket Pipelines - Versioned Workflow
Bitbucket Pipelines is a built-in CI/CD service in Bitbucket that allows you to automatically build, test, and deploy your code. Combined with Atlas, you can manage database schema changes with confidence.
In this guide, we will demonstrate how to use Bitbucket Pipelines and Atlas to set up CI/CD pipelines for your database schema changes using the versioned migrations workflow.
Prerequisites
Installing Atlas
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
After installing Atlas locally, log in to your organization by running the following command:
atlas login
Creating a bot token
To report CI run results to Atlas Cloud, create an Atlas Cloud bot token by following these instructions and copy it.
Next, in your Bitbucket repository, go to Repository settings -> Repository variables and create a new secured variable named ATLAS_TOKEN. Paste your token in the value field.
Creating a secret for your database URL
To avoid having plain-text database URLs that may contain sensitive information in your configuration files, create another secured variable named DATABASE_URL and populate it with the URL (connection string) of your database.
To learn more about formatting URLs for different databases, see the URL documentation.
Creating a Bitbucket access token (optional)
Atlas can post lint reports as comments on pull requests. To enable this, create a Bitbucket app password with pullrequest:write permissions. Then, add it as a secured variable named BITBUCKET_ACCESS_TOKEN.
Offline Access
Unlike GitHub/GitLab/CircleCI integrations, Bitbucket Pipelines does not automatically cache Atlas grants for Atlas Action runs. To ensure Atlas Cloud is not a single point of failure in your pipeline, configure an external cache for .atlas and sync it with ~/.atlas before and after running Atlas actions.
definitions:
caches:
atlas-grant: .atlas
pipelines:
default:
- step:
caches:
- atlas-grant
script:
- mkdir -p ~/.atlas
- cp -a .atlas/. ~/.atlas/ 2>/dev/null || true
- pipe: docker://arigaio/atlas-action:v1
variables:
ATLAS_ACTION: migrate/lint
ATLAS_TOKEN: $ATLAS_TOKEN
- mkdir -p .atlas
- cp -a ~/.atlas/. .atlas/ 2>/dev/null || true
Versioned Migrations Workflow
In the versioned workflow, changes to the schema are represented by a migration directory in your codebase. Each file in this directory represents a transition to a new version of the schema.
Based on our blueprint for Modern CI/CD for Databases, our pipeline will:
- Lint new migration files whenever a pull request is opened.
- Push the migration directory to the Schema Registry when changes are merged to the main branch.
- Apply new migrations to our database.
In this guide, we will walk through each of these steps and set up a Bitbucket Pipelines configuration to automate them.
The full source code for this example can be found in the atlas-examples/versioned repository.
Defining the desired schema
First, define your desired database schema. Create a file named schema.sql with the following content:
CREATE TABLE "users" (
"id" bigserial PRIMARY KEY,
"name" text NOT NULL,
"active" boolean NOT NULL,
"address" text NOT NULL,
"nickname" text NOT NULL,
"nickname2" text NOT NULL,
"nickname3" text NOT NULL
);
CREATE INDEX "users_active" ON "users" ("active");
Creating the Atlas configuration file
Create a configuration file for Atlas named atlas.hcl with the following content:
variable "database_url" {
type = string
default = getenv("DATABASE_URL")
description = "URL to the target database to apply changes"
}
env "dev" {
src = "file://schema.sql"
url = var.database_url
dev = "docker://postgres/15/dev?search_path=public"
migration {
dir = "file://migrations"
}
diff {
concurrent_index {
add = true
drop = true
}
}
}
Generating your first migration
Now, generate your first migration by comparing your desired schema with the current (empty) migration directory:
atlas migrate diff initial --env dev
This command will automatically create a migrations directory with a migration file containing the SQL statements needed to create the users table and index, as defined in our file linked at src in the dev environment.
Pushing a migration directory to Atlas Cloud
Run the following command from the parent directory of your migration directory to create a "migration directory" repository in your Atlas Cloud organization:
atlas migrate push bitbucket-atlas-action-versioned-demo --env dev
This command pushes the migrations directory linked in the migration dir field in the dev environment defined in our atlas.hcl to a project in the Schema Registry called bitbucket-atlas-action-versioned-demo.
Atlas will print a URL leading to your migrations on Atlas Cloud. You can visit this URL to view your migrations.
Setting up Bitbucket Pipelines
Create a bitbucket-pipelines.yml file in the root of your repository with the following content:
# This is an example Starter pipeline configuration
# Use a skeleton to build, test and deploy using manual and parallel steps
# -----
# You can specify a custom docker image from Docker Hub as your build environment.
image: atlassian/default-image:3
# List of available ATLAS_ACTION can be found at:
# https://github.com/ariga/atlas-action
#
# For input variables, please refer to the README.md of the action
# then add the prefix `ATLAS_INPUT_` to the input name.
#
# For example, if the input name is `working-directory`, then the variable name should be `ATLAS_INPUT_WORKING_DIRECTORY`
# The output will be saved in the file `.atlas-action/outputs.sh` and can be sourced to get the output variables
# And the directory can be changed by setting the `ATLAS_OUTPUT_DIR` variable.
#
# The `ATLAS_TOKEN` is required for all actions.
definitions:
services:
# Run Postgres database to simulate the production database
# This is only for demo purposes.
# We can replace this with the proxy to connect to the production database.
fake-db:
image: postgres:15
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
commonItems:
atlas-action-variables: &atlasVars
ATLAS_TOKEN: $ATLAS_TOKEN # Required
# The access token is required to comment on the PR
# It must have Pull requests/Write permission
BITBUCKET_ACCESS_TOKEN: $BITBUCKET_ACCESS_TOKEN
# To connect to the service running outside the pipeline,
# we need to use the host.docker.internal to connect to the host machine
DATABASE_URL: postgres://postgres:postgres@host.docker.internal:5432/postgres?sslmode=disable&search_path=public
pipelines:
pull-requests:
'**':
- step:
name: 'Lint Migrations'
script:
- name: Lint migrations
pipe: docker://arigaio/atlas-action:v1
variables:
<<: *atlasVars
ATLAS_ACTION: migrate/lint # Required
ATLAS_INPUT_ENV: dev
ATLAS_INPUT_DIR_NAME: "bitbucket-atlas-action-versioned-demo"
- cat .atlas-action/outputs.sh
- source .atlas-action/outputs.sh
services:
- fake-db
branches:
master:
- step:
name: 'Push and Apply Migrations'
script:
- name: Push migrations
pipe: docker://arigaio/atlas-action:v1
variables:
<<: *atlasVars
ATLAS_ACTION: migrate/push # Required
ATLAS_INPUT_ENV: dev
ATLAS_INPUT_DIR_NAME: "bitbucket-atlas-action-versioned-demo"
- name: Apply migrations
pipe: docker://arigaio/atlas-action:v1
variables:
<<: *atlasVars
ATLAS_ACTION: migrate/apply # Required
ATLAS_INPUT_ENV: dev
ATLAS_INPUT_DIR: "atlas://bitbucket-atlas-action-versioned-demo"
- cat .atlas-action/outputs.sh
- source .atlas-action/outputs.sh
services:
- fake-db
This configuration uses master as the default branch name. If your Bitbucket repository uses a different default branch (such as main), update the branches: section accordingly:
branches:
main: # Change to match your default branch
Let's break down what this pipeline configuration does:
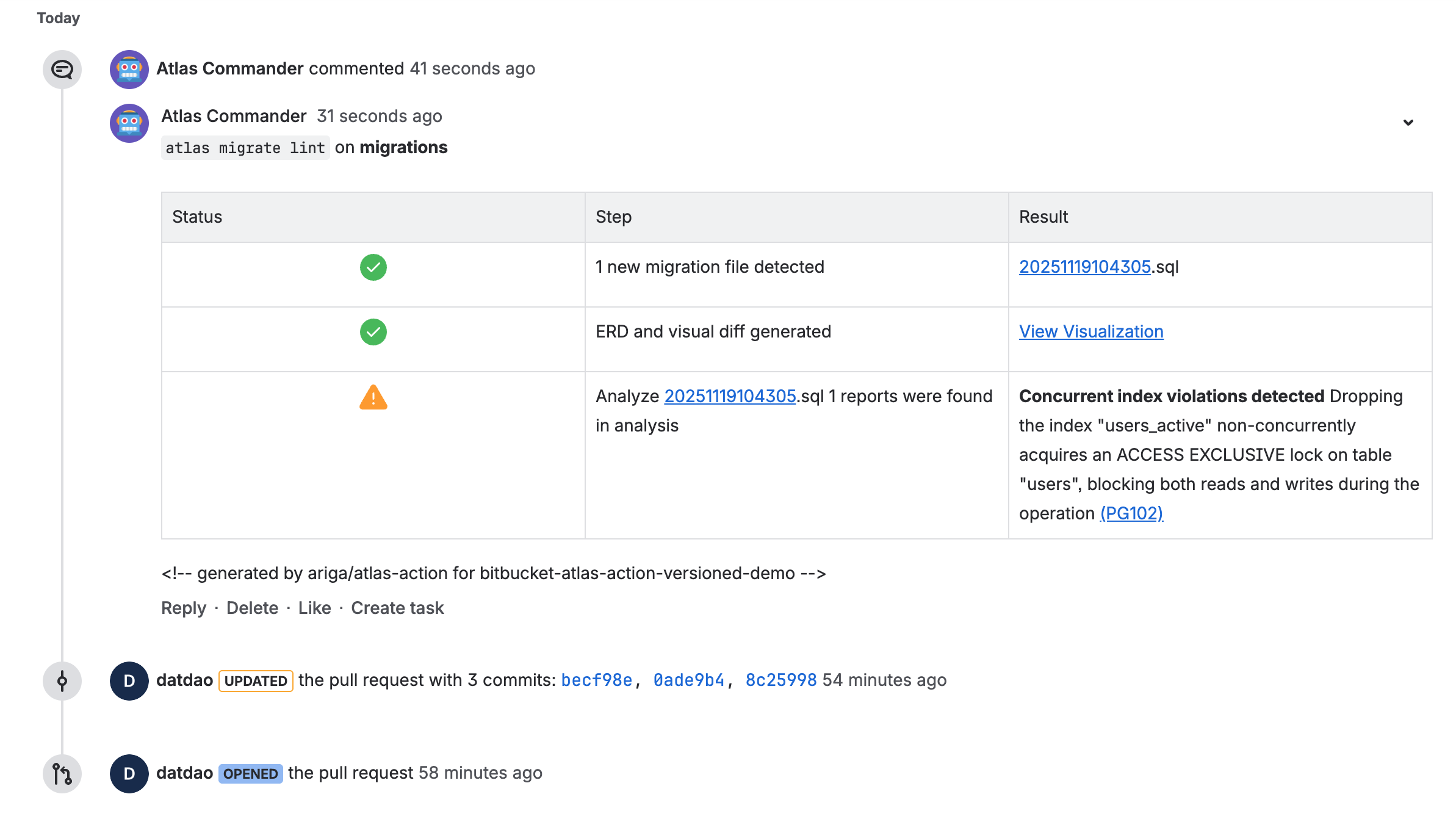
- The
migrate/lintstep runs on every pull request. When new migrations are detected, Atlas will lint them and post a report as a comment on the pull request. This helps you catch issues early in the development process.
-
After the pull request is merged into the master branch, the
migrate/pushstep will push the new state of the migration directory to the Schema Registry on Atlas Cloud. -
The
migrate/applystep will then deploy the new migrations to your database.
Testing our pipeline
Let's take our pipeline for a spin:
- Locally, create a new branch and modify your
schema.sqlfile to remove the index:schema.sqlCREATE TABLE "users" (
"id" bigserial PRIMARY KEY,
"name" text NOT NULL,
"active" boolean NOT NULL,
"address" text NOT NULL,
"nickname" text NOT NULL,
"nickname2" text NOT NULL,
"nickname3" text NOT NULL
); - Generate a new migration with
atlas migrate diff drop_users_active --env dev. This will create a migration file that drops the index. - Commit and push the changes (both
schema.sqland the new migration file in themigrationsdirectory). - In Bitbucket, create a pull request for the branch you just pushed.
- View the lint report generated by Atlas. Follow the links to see the changes visually on Atlas Cloud.
- Merge the pull request.
- When the pipeline has finished running, check your database to verify that the changes were applied.
Wrapping up
In this guide, we demonstrated how to use Bitbucket Pipelines with Atlas to set up a modern CI/CD pipeline for versioned database migrations. Here's what we accomplished:
- Automated migration linting on every pull request to catch issues early
- Centralized migration management by pushing to Atlas Cloud's Schema Registry
- Automated deployments to your target database when changes are merged
For more information on the versioned workflow, see the Versioned Migrations documentation.
Next steps
- Learn about Atlas Cloud for enhanced collaboration
- Explore migration testing to validate your migrations
- Read about declarative migrations as an alternative workflow
- Check out the Bitbucket Pipes reference for all available actions