Optimal data alignment in tables (PG110)
Alignment and Padding in PostgreSQL
When creating a new table, columns of different data types take up different amounts of disk space. The order in which the columns are written determines the amount of space that is used by the rows in the table. Postgres may add padding to columns with smaller sizes to fulfill alignment requirements of the data type of the consecutive column with a larger size.
For example, let’s consider a table with four smallint and one bigint type columns. When a column with a smaller size, such as a smallint (2 bytes), has a consecutive column with a larger size, such as bigint (8 bytes), Postgres adds 6 bytes of padding to the column of type smallint in order to fulfill an alignment requirement of 8 bytes for the consecutive bigint column. However, the space used in padding (6 bytes) can be utilized by rearranging the three other smallint type columns from the table before the bigint type column:

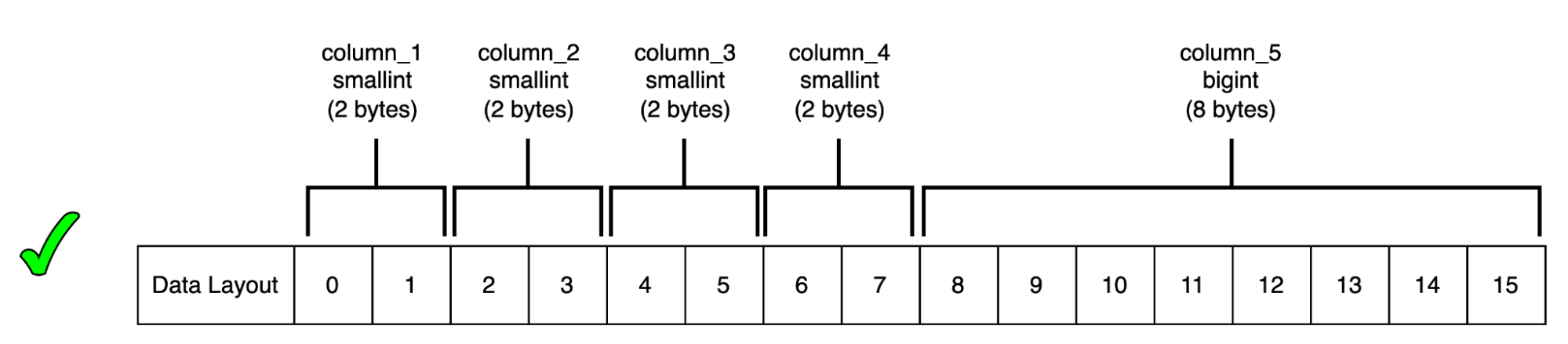
The catalog pg_type stores information about alignment requirements for various data types. You can access the typealign column of this catalog table in order to determine alignment requirements for data types. To learn more about the catalog pg_type and interpretation of the typealign column, visit the official documentation here.
Save up on precious space with optimal data alignment
Creating a table with optimal data alignment can help minimize the amount of required disk space. This document describes how we can save space in a database just by changing the order of columns. Let’s see it in action.
Example
Consider the following table on a 64-bit system.
CREATE TABLE users (
user_id bigint PRIMARY KEY,
active_status boolean,
data_balance integer,
plan_period smallint
);
Here is what a portion of the table might look like after inserting values:
SELECT
*
FROM
users
user_id | active_status | data_balance | plan_period
---------+---------------+--------------+-------------
0 | f | 731147 | 267
1 | t | 901448 | 26
2 | t | 496823 | 24
3 | t | 985877 | 280
4 | f | 857124 | 83
.
.
.
1999995 | f | 993259 | 83
1999996 | f | 926033 | 332
1999997 | f | 889133 | 280
1999998 | t | 943793 | 7
1999999 | t | 550192 | 146
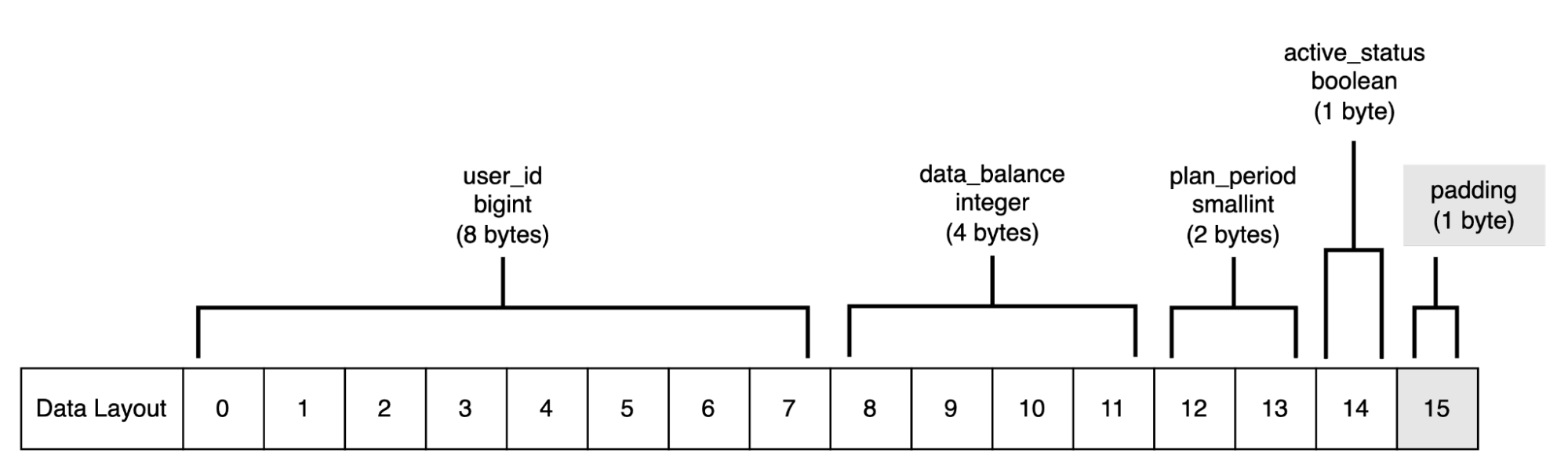
Each tuple in the table takes up 24 bytes of total memory without the header. The user_id occupies the first 8 bytes.
Here, the active_status column is of type boolean and takes up only one byte. However, because the next consecutive column data_balance is an integer with size of 4 bytes, PostgreSQL automatically adds 3 bytes of padding to active_status so its size can match with the 4 bytes size of the consecutive data_balance column.
The second 8 bytes of the row are occupied by 1 byte of active_status, 3 bytes of padding, and then 4 bytes of data_balance.
Lastly, the plan_period column has a size of only 2 bytes. However, PostgreSQL adds 6 bytes of padding in order to complete the 8 bytes for the end of the row. The following table displays the data:
| Column | Type | Size | Padding |
|---|---|---|---|
| user_id | bigint | 8 bytes | None |
| active_status | boolean | 1 byte | 3 bytes |
| data_balance | integer | 4 bytes | None |
| plan_period | smallint | 2 bytes | 6 bytes |

Now, let’s see how much space the table takes with the following command:
SELECT pg_size_pretty(pg_relation_size('users'));
pg_size_pretty
----------------
100 MB
(1 row)
Our table occupies 100 MB of space. Let’s see how we can optimize the occupied space by rearranging the columns.
Let’s create the same table with the rearranged rows as follows:
CREATE TABLE users_optimized (
user_id bigint PRIMARY KEY,
data_balance integer,
plan_period smallint,
active_status boolean
);
Here is what a portion of the table might look like after inserting values:
SELECT
*
FROM
users_optimized
user_id | data_balance | plan_period | active_status
---------+--------------+-------------+---------------
0 | 730878 | 267 | f
1 | 410081 | 329 | t
2 | 207715 | 181 | t
3 | 332717 | 360 | f
4 | 967756 | 313 | t
.
.
.
1999995 | 692890 | 363 | t
1999996 | 878947 | 338 | f
1999997 | 525196 | 325 | f
1999998 | 170783 | 344 | t
1999999 | 97850 | 201 | t
Now, let’s see how much space the table takes with the following command:
SELECT pg_size_pretty(pg_relation_size(users_optimized));
pg_size_pretty
----------------
84 MB
(1 row)
Awesome! We have saved almost 16 MB of space (which is also 16% in our example), just by changing the order of the columns.
Let’s understand how that happened:
The user_id occupies the first 8 bytes.
Next, data_balance is an integer that takes up 4 bytes, followed by the plan_period column which has a size of only 2 bytes, followed by 1 byte of active_status and then 1 byte of padding for the end of the row.
In this case, each tuple in the table takes 16 bytes of total memory without the header, and only 1 byte of padding is used, in contrast to 24 bytes of total memory with 9 bytes of total padding involved in our previous example. Here is the data:
| Column | Type | Size | Padding |
|---|---|---|---|
| user_id | bigint | 8 bytes | None |
| data_balance | integer | 4 bytes | None |
| plan_period | smallint | 2 bytes | None |
| active_status | boolean | 1 byte | 1 byte |
Determining optimal data alignment for a table is easy with Atlas CI
As we have observed in the previous section, creating a table with non-optimal data alignment can cost more space, and thus more money. At the same time, calculating the disk space and determining the best arrangement of columns manually can be confusing and error-prone.
With the help of Atlas CI, you can now easily check whether your table alignment is optimal. If the alignment is not optimal, Atlas "CI for databases" will suggest the best possible order of columns to make the alignment optimal and thus help you save maximum space (and money!).
Teams using GitHub that wish to ensure all changes to their database schema are safe can use the Atlas GitHub Action. If you’re just getting started, you can visit the documentation to set-up Atlas CI GitHub action
Let’s create a migration file in Atlas format with the following SQL command:
CREATE TABLE users (
user_id bigint PRIMARY KEY,
active_status boolean,
data_balance integer,
plan_period smallint
);
Once the Atlas CI check is completed, you should see the following code suggestion in your pull request:
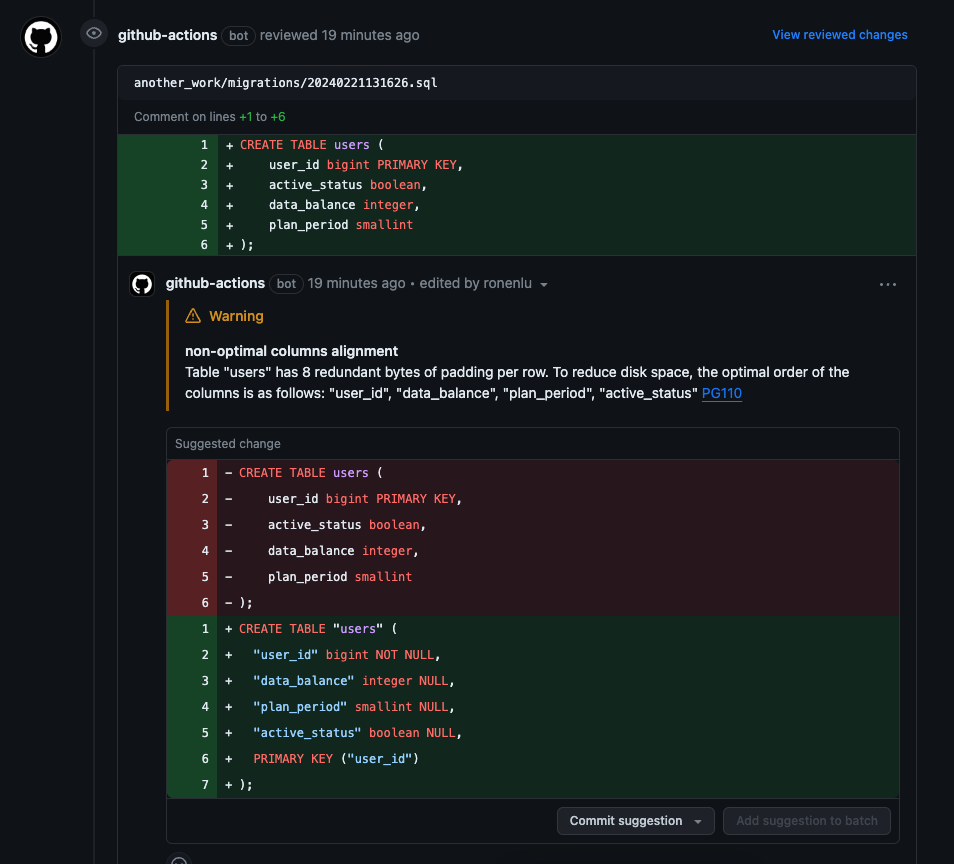
Awesome! The Atlas CI check has analyzed the migration file and suggested the best possible arrangement of columns in order to optimize the space taken by padding per row.
Atlas CI provides different Analyzer implementations that are useful for determining the safety of migration scripts. To learn more about other checks currently supported by Atlas CI, visit the documentation about analyzers here.
Conclusion
In this section, we learned about how we can reduce disk space costs without removing any data, just by arranging the table columns in an efficient order to reduce padding space.
Additionally, we have also learned how using Atlas CI can help us determine the best optimal order of columns in a table, removing the hassle of manually calculating the disk cost before and after rearranging columns.
Need More Help?
Join the Ariga Discord Server for early access to features and the ability to provide exclusive feedback that improves your Database Management Tooling.
Sign up to our newsletter to stay up to date about Atlas, our OSS database schema management tool, and our cloud platform Atlas Cloud.